一、概述
SQLite 将整个数据库存储在一个文件中,其格式在SQLite 文件数据库文件格式 文档[3]中进行了描述。每个数据库文件都存储在一个文件系统中,大概由主机操作系统提供。主机应用程序不是直接与操作系统交互,而是需要提供一个适配器组件来实现SQLite 虚拟文件系统接口(在[1]中描述)。适配器组件负责将 SQLite 对VFS接口的调用转换为对操作系统提供的文件系统接口的调用。这种安排如图所示 1 .
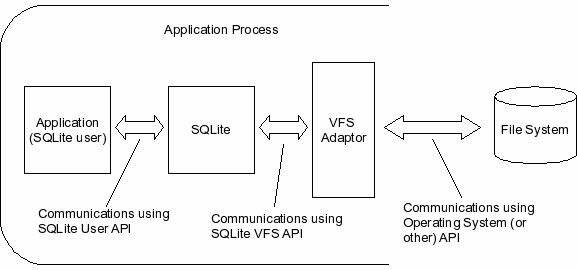
图1 - 虚拟文件系统 (VFS) 适配器
尽管设计一个使用VFS 接口来读取和更新存储在文件系统中的数据库文件内容的系统很容易,但是这样的系统需要解决几个复杂的问题:
SQLite 需要实现原子和持久事务(ACID 首字母缩写词中的“A”和“D”),即使应用程序、操作系统或电源故障发生在更新数据库文件的中途或之后不久。
为了在面对潜在的应用程序、操作系统或电源故障时实现原子事务,数据库编写者在写入数据库文件之前,将他们将要修改的数据库文件的那些部分的副本写入第二个文件,即日志文件. 如果在修改数据库文件时发生故障,SQLite 可以根据日志文件的内容重建原始数据库(在尝试修改之前) 。
需要 SQLite 来实现隔离事务(ACID 首字母缩写词中的“I”)。
这是通过使用 VFS 适配器提供的文件锁定设施来序列化写入器(写入事务)并防止读取器(读取事务)在写入器更新数据库文件的中途访问数据库文件来完成的。
出于性能原因,尽量减少从文件系统 读取和写入的数据量是有利的。
正如人们可能预料的那样,通过在主内存中缓存部分数据库文件,可以最大限度地减少从数据库文件中读取的数据量。此外,作为同一写入事务的一部分的数据库文件的多个更新可以缓存在主内存中并一起写入文件,从而允许更有效的 IO 模式并消除如果数据库的一部分可能发生的冗余写入操作文件在单个写入事务中被多次修改。
以上几点的系统要求参考。
这篇文档详细描述了SQLite是如何使用VFS适配器组件提供的API来解决上述问题以及实现上述列举的策略的。它还指定了对 VFS 适配器提供访问的系统属性所做的假设。例如,第 2.2节介绍了在更新数据库文件时发生电源故障时可能发生的数据损坏程度的具体假设。
本文档没有指定 VFS 适配器组件必须实现的接口的详细信息,留给 [1]。
1.1. 与其他文件的关系
与 C-API 要求相关:
- 打开一个连接。
- 关闭连接。
SQL要求相关:
- 打开一个只读事务。
- 终止只读事务。
- 打开一个读写事务。
- 提交读写事务。
- 回滚读写事务。
- 开立对账单交易。
- 提交声明交易。
- 回滚语句事务。
- 提交多文件事务。
与文件格式要求相关:
- 固定(读取)数据库页面。
- 取消固定数据库页面。
- 修改数据库页面的内容。
- 将新页面附加到数据库文件。
- 从数据库文件末尾截断一页。
1.2. 文档结构
本文档的第2部分描述了对 VFS 适配器组件提供访问的系统所做的各种假设。[1]中介绍了 VFS 实现所需的基本能力和功能以及 VFS 接口的描述 。第 2节通过更详细地描述本文档中介绍的算法所依赖的 VFS 实现的假设来补充这一点。其中一些假设与性能问题有关,但大多数与修改数据库文件中途发生故障后文件系统的预期状态有关。
第3节介绍了数据库连接的概念,它是用于访问数据库文件的文件句柄和内存缓存的组合。它还描述了创建(打开)新数据库连接和销毁(关闭)数据库连接时所需的 VFS 操作。
第5节描述了打开读取事务和从数据库文件读取数据所需的步骤。
第6节描述了打开写事务并将数据写入数据库文件所需的步骤。
第7节描述了中止的 写入事务可以回滚(还原)的方式,这可能是由于显式用户指令的结果,也可能是因为在 SQLite 更新数据库文件的中途发生应用程序、操作系统或电源故障。
4.2 节描述了一些算法,用于准确确定页面缓存缓存了数据库文件的哪些部分,以及它们对所需 VFS 操作的数量和性质的影响。在本文档中包含页面缓存,这主要是一个实现细节,乍一看似乎很奇怪。然而,有必要承认和描述页面缓存,以便更完整地解释 SQLite 执行的 IO 的性质和数量。
1.3. 词汇表
准备好这个文档后,让词汇表一致,然后在这里添加一个词汇表。
2. VFS适配器相关假设
本节记录了对 VFS 适配器提供访问的系统所做的那些假设。2.2节中提到的假设 特别重要。如果这些假设不成立,那么电源或操作系统故障可能会导致 SQLite 数据库损坏。
2.1. 性能相关假设
SQLite 使用本节中的假设来尝试加快读取和写入数据库文件的速度。
假设按顺序将一系列连续的数据块写入文件比以任意顺序写入相同的块更快。
2.2. 系统故障相关假设
在操作系统或电源出现故障的情况下,可用的文件系统软件和存储硬件的各种组合提供不同级别的保证,以确保在故障之前或故障期间写入文件系统的数据的完整性。为了安全地修改数据库文件,SQLite 需要执行的 IO 操作的确切组合取决于目标平台的确切特征。
本节描述 SQLite 在电源或系统故障后对文件系统内容所做的假设。换句话说,它描述了此类事件可能导致的文件和文件系统损坏的程度。
SQLite 使用数据库文件文件句柄的 xDeviceCharacteristics() 和 xSectorSize() 方法查询文件系统特征的实现。这两个方法只会在打开数据库文件的文件句柄上调用。它们不会为 日志文件、主日志文件或 临时数据库文件调用。
通过调用 xSectorSize() 方法确定的文件系统扇区大小值是 2 的幂值,介于 512 和 32768 之间,包括对确定方式的确切引用。SQLite 假定底层存储设备将数据存储在每个扇区大小字节的块中,扇区。还假设每个文件的每个对齐的 扇区大小字节块都存储在单个设备扇区中。如果文件的大小不是扇区大小 字节的精确倍数,则最终设备扇区部分为空。
通常,SQLite 假设如果在更新扇区的任何部分时发生电源故障,那么整个设备扇区的内容在恢复后都是可疑的。在写入文件内扇区的任何部分后,假设修改后的扇区内容保存在系统某处(主内存、磁盘缓存等)的易失性缓冲区中。SQLite 不会假设更新的数据已经到达持久存储介质,直到它通过调用 VFS xSync() 方法成功同步了相应的文件之后。同步文件会导致对文件的所有修改,直到提交到持久存储。
基于以上所述,SQLite 是围绕文件系统模型设计的,在该模型中,写入文件的任何扇区都被视为处于瞬态状态,直到文件已成功 同步。如果扇区处于瞬态状态时发生电源或系统故障,则无法预测其恢复后的内容。它可能被正确写入、根本没有写入、被随机数据覆盖,或者它们的任何组合。
例如,如果给定文件系统的扇区大小为 2048 字节,SQLite 打开一个文件并将 1024 字节的数据块写入文件的偏移量 3072,那么根据模型,文件的第二个扇区是在瞬态。如果在下一次调用文件句柄上的 xSync() 之前或期间发生电源故障或操作系统崩溃,则在系统恢复之后,SQLite 假定字节偏移量 2048 和 4095 之间的所有文件数据(含)都是无效的。它还假设文件的第一个扇区(包含从字节偏移 0 到 2047 的数据)是有效的,因为它在崩溃发生时不处于瞬态状态。
假设任何和所有处于瞬态状态的扇区都可能在电源或系统故障后损坏是一种非常悲观的方法。一些现代系统提供比这更复杂的保证。SQLite 允许 VFS 实现在运行时指定当前平台支持零个或多个以下属性:
安全附加属性。如果系统支持 安全追加属性,则意味着当文件被扩展时,新数据会在文件本身的大小更新之前写入持久媒体。这保证如果在文件扩展后发生故障,恢复后扩展文件的写操作将看起来已经成功或根本没有发生。文件的扩展区域中不可能出现无效或垃圾数据。
原子写入属性。支持此属性的系统还指定了它能够写入的块的大小。有效大小是大于 512 的 2 的幂。如果写操作修改了一个n字节的块,其中n是支持原子写的块大小之一,那么n字节 的对齐写不可能 导致数据损坏。如果在此类写入操作之后和同步适用的文件句柄之前发生故障 , 然后在恢复之后,它会看起来好像写操作成功或根本没有发生。不可能只有写入操作指定的部分数据被写入持久性介质,写入操作所跨越的扇区的任何内容也不可能被垃圾数据替换,因为通常假设是.
顺序写入属性。支持 顺序写入属性的系统保证对同一文件系统中文件的各种写入操作按照应用程序执行的相同顺序写入持久介质,并且每个操作在下一个操作之前完成开始了。如果系统支持顺序写入 属性,则用于确定文件系统在发生故障后的可能状态的模型是不同的。
如果系统支持顺序写入,则假定 同步文件系统中的任何文件会将所有文件(不仅仅是同步文件)上的所有写入操作刷新到持久介质。如果确实发生故障,则不知道自上次同步文件以来 SQLite 是否执行了任何写操作。SQLite 能够假定,如果未知状态的写操作按照它们发生的顺序排列:
- 前n 个操作将成功执行,
- 下一个操作将它修改的所有设备扇区置于瞬态状态,以便在恢复后每个扇区可能被部分写入、完全写入、根本不写入或填充垃圾数据,
- 其余操作不会对文件系统的内容产生任何影响。
2.2.1. 故障相关假设详细信息
本节描述父节中提出的假设如何应用于 VFS 为修改文件系统的内容而向 SQLite 提供的各个 API 函数和操作。
SQLite 使用以下四种操作的组合来操作文件系统的内容:
- 创建文件操作。SQLite 可以通过调用 sqlite3_io_methods 对象的 xOpen() 方法在文件系统中创建新文件。
- 删除文件操作。SQLite 可以通过调用 sqlite3_io_methods 对象的 xDelete() 方法从文件系统中删除文件。
- 截断文件操作。SQLite 可以通过调用 sqlite3_file 对象的 xTruncate() 方法来截断现有文件。
- 写文件操作。SQLite 可以通过调用 sqlite3_file 对象的 xWrite() 方法逐个文件地修改内容和增加文件的大小。
此外,所有 VFS 实现都需要提供 同步文件操作,通过 sqlite3_file 对象的 xSync() 方法访问,用于将文件上的创建、写入和截断操作刷新到持久存储介质。
本节中的形式化假设指的是系统故障 事件。在此上下文中,这应解释为导致系统停止运行的任何故障。例如电源故障或操作系统崩溃。
在文件成功同步之前, SQLite 不会假设创建文件操作实际上已经修改了持久存储中的文件系统记录。
如果系统故障发生在“创建文件”操作期间或之后,但在同步创建的文件之前,则 SQLite 假定创建的文件可能在系统恢复后不存在。
当然也有可能是系统恢复后确实存在。
如果 SQLite 执行“创建文件”操作,然后同步创建的文件,则 SQLite 假定与“创建文件”操作对应的文件系统修改已提交到持久媒体。假定如果在文件成功 同步后的任何时间发生系统故障,则该文件保证会在系统恢复后出现在文件系统中。
删除文件操作( 通过调用 VFS xDelete() 方法调用)被假定为原子和持久操作。
如果在“删除文件”操作(调用 VFS xDelete() 方法)成功返回后的任何时间发生系统故障,则假定文件系统在系统恢复后将不包含已删除的文件。
如果在“删除文件”操作期间发生系统故障,则假定在系统恢复后文件系统将包含被删除的文件,该文件处于尝试操作之前的状态,或者根本不包含该文件. 假定文件不可能纯粹由于“删除文件”操作期间发生故障而损坏。
假定截断文件操作 的效果在相应文件同步之后才会持久 。
如果在“截断文件”操作期间或之后但在同步 截断文件之前发生系统故障,则 SQLite 假定截断文件的大小与要截断的大小一样大或更大.
如果在“截断文件”操作期间或之后但在同步 截断的文件之前发生系统故障,则假定文件的内容不超过要截断的大小未损坏。
上述两个假设可能被解释为意味着如果系统故障发生在文件截断之后但在截断的文件被同步之前,则截断点之后的文件内容可能不可信。它们可能包含原始文件数据,也可能包含垃圾。
如果 SQLite 执行了“截断文件”操作,然后同步了截断的文件,则 SQLite 假定与“截断文件”操作对应的文件系统修改已提交到持久媒体。假定如果在文件成功 同步后的任何时间发生系统故障,则文件截断的影响保证会在恢复后出现在文件系统中。
写入文件操作修改文件系统中现有文件的内容 。它还可能会增加文件的大小。在相应的文件被同步之前,写入文件操作的效果不会被假定为持久的 。
如果在“写入文件”操作期间或之后但在同步 相应文件之前发生系统故障,则假定 写入文件操作跨越的所有扇区的内容在系统恢复后都是不可信的。这包括实际未被写入文件操作修改的扇区区域。
如果在将N字节对齐写入 文件后但在文件成功同步之前,支持大小为N字节的块的原子写入属性 的系统发生系统故障 ,则假定在恢复后所有扇区跨越写入操作已正确更新,或者根本没有修改任何扇区。
如果系统故障发生在支持 安全附加的系统上,在写入操作之后将数据附加到文件的末尾而不修改任何现有文件内容但在文件成功同步之前,则假设在恢复之后数据已正确附加到文件,或者文件大小保持不变。假定文件不可能被扩展但填充了不正确的数据。
系统恢复后,如果设备扇区被视为 A21008 所定义的不可信,并且 A21011 或 A21012 均不适用于写入的字节范围,则无法假设恢复后扇区的内容。假设这样的扇区可能被正确写入,根本没有写入,填充有垃圾数据或其任何组合。
如果在导致文件增长的“写文件”操作期间或之后发生系统故障,但在同步相应文件之前,则假定恢复后文件的大小与原来一样大或更大最近同步的时间。
如果系统支持顺序写入属性,则可以对从系统故障恢复后的文件系统状态做出进一步的假设。具体来说,假设创建、截断、删除和写入文件操作以与 SQLite 执行的顺序相同的顺序应用于持久表示。此外,假定文件系统会一直等到一个操作安全地写入持久性介质,然后再尝试下一个操作,就像在每个操作之后 同步相关文件一样。
如果在支持顺序写入属性 的系统上发生系统故障 ,则假定在最后一次同步任何文件之前完成的所有操作 都已成功提交到持久介质。
如果在支持顺序写入属性 的系统上发生系统故障 ,则假定文件系统在恢复后可能处于的一组可能状态与自上次以来执行的每个写入操作相同最近一次同步文件本身之后是同步文件操作,并且系统故障可能发生在任何写入或同步文件操作期间。
3.数据库连接
在本文档中,术语数据库连接的含义与人们可能假设的含义略有不同。sqlite3_open()和sqlite3_open16()
API(参考)返回的句柄称为数据库句柄。数据库连接是使用单个文件句柄与单个数据库文件的连接,该文件句柄在连接的生命周期内保持打开状态。使用 SQL ATTACH 语法,
可以通过单个数据库句柄访问多个数据库连接。或者,使用 SQLite 的共享缓存模式特性,多个
数据库句柄可以访问一个数据库连接。
通常,每当用户在真实数据库文件(而非内存数据库)上打开新的数据库句柄或使用 SQL ATTACH 语法将数据库文件附加到现有数据库连接时,都会打开一个新的数据库连接。但是,如果启用共享缓存模式功能,则可以通过现有数据库连接访问数据库文件。有关 共享高速缓存模式的更多信息,请参阅参考资料。打开新连接所需的各种 IO 操作在本文档 的3.1节中有详细说明。
类似地,当用户关闭在真实数据库文件上打开的数据库句柄或使用 ATTACH 机制将一个或多个真实数据库文件附加到它时,或者当真实数据库文件从使用 DETACH 语法的数据库连接。同样,如果 启用共享缓存模式则例外。在这种情况下,数据库连接在其用户数达到零之前不会关闭。关闭数据库连接所需的 IO 相关步骤在3.2节中描述。
完成第 4 节和第 5 节后,回到这里,看看我们是否可以添加与每个数据库连接关联的状态项列表,以使事情更容易理解。即每个数据库连接都有一个文件句柄、页面缓存中的一组条目、预期的页面大小等。
3.1. 打开新连接
本节介绍创建新数据库连接时发生的 VFS 操作。
打开一个新的数据库连接是一个两步过程:
- 在数据库文件上打开文件句柄。
- 如果第 1 步成功,将尝试 使用新的文件句柄从数据库文件 中读取数据库文件头。
在上述过程的第 2 步中,数据库文件在读取之前未被锁定。这是第5节中描述的锁定规则的唯一例外。
尝试读取数据库文件头的原因 是为了确定数据库文件使用的页面大小。 因为如果不至少持有数据库文件上的共享锁就不可能确定页面大小(因为在读取数据库文件头后一些其他数据库连接可能已经更改它),从数据库读取的值 文件头被称为预期页面大小。
当需要新的数据库连接时,SQLite 将尝试打开数据库文件的文件句柄。如果尝试失败,则不会创建新的数据库连接并返回错误。
当需要新的数据库连接时,在打开新的文件句柄后,SQLite 将尝试读取数据库文件的前 100 个字节。如果尝试由于打开的文件小于 100 字节以外的任何其他原因失败,则文件句柄将关闭,不会创建新的数据库连接,而是返回错误。
如果从新打开的数据库文件中成功读取了数据库文件头,则连接预期页面大小应设置为存储在数据库头 的页面大小字段中的值。
如果无法从新打开的数据库文件中读取数据库文件头(因为文件的大小小于 100 字节),则应将连接期望的页面大小设置为 SQLITE_DEFAULT_PAGESIZE 选项的编译时值。
3.2. 关闭连接
本节介绍关闭(销毁)现有数据库连接时发生的 VFS 操作。
关闭数据库连接是一件简单的事情。关闭打开的 VFS 文件句柄并释放内存中页面缓存相关资源。
当数据库连接关闭时,SQLite 将在 VFS 级别关闭关联的文件句柄。
当数据库连接关闭时,所有关联的页面缓存条目都将被丢弃。
4.页面缓存
SQLite 数据库文件的内容被格式化为一组固定大小的页面。有关所用格式的完整描述,请参阅[3]。用于特定数据库的页面大小作为数据库文件头的一部分存储在文件前 100 字节内的已知偏移量处。SQLite 对数据库文件执行的几乎所有读写操作都是在大小为页大小字节的数据块上完成的。
在单个进程中运行的所有 SQLite 数据库连接共享一个页面缓存。页面缓存以每页为基础缓存从主内存中的数据库文件读取的数据。当 SQLite 需要来自数据库文件的数据来满足数据库查询时,它会在从数据库文件加载数据之前检查 页面缓存以获取所需数据库页面的可用缓存版本。如果找不到可用的缓存条目,则从数据库文件中加载数据库页面数据,将其缓存在页面缓存中以防以后再次需要相同的数据。因为假定从数据库文件读取比从主内存读取慢一个数量级,所以在页面缓存中缓存数据库页面内容以最小化对数据库文件执行的读取操作的数量是显着的性能增强。
页缓存还用于缓冲数据库写操作 。当 SQLite 需要修改构成数据库文件的多个数据库页面 之一时,它首先修改页面缓存中页面的缓存版本。此时该页面被认为是“脏”页面。稍后,“脏”页面的新内容通过 VFS 接口从页面缓存复制到数据库文件中。在页面缓存中缓冲写入可以减少数据库文件所需的写入操作数(在同一页面更新两次的情况下),并允许根据2.1节中概述的假设进行优化.
数据库读写操作,以及它们与页缓存交互和使用的方式,分别在本文档 的第5节和第 6节中进行了详细描述 。
在任何时候,页面缓存都包含零个或多个页面缓存条目,每个条目都有以下相关数据:
对关联数据库连接 的引用。页面缓存中的每个条目都与一个数据库连接相关联;创建条目的数据库连接。页面缓存条目仅由创建它的数据库连接使用。页面缓存条目不在 数据库连接之间共享。
缓存页面的页码。页面在数据库文件中从第 1 页开始按顺序编号(第 1 页从字节偏移量 0 开始)。有关详细信息,请参阅[3]。
缓存数据 ;大小为页大小字节 的 blob 。
上面列表中的前两个元素,关联的数据库连接和页码,唯一标识 页面缓存条目。任何时候页面缓存都不能包含数据库连接和页码相同的两个条目。或者,换句话说,单个数据库连接永远不会在页面缓存中缓存多个数据库页面副本。
根据以下定义, 在任何时候,每个页面缓存条目都可以被称为干净页面、不可写脏页或可写脏页:
-
干净页面是缓存数据当前与数据库文件相应页面内容匹配的页面。该页面从文件加载后未被修改。
-
脏页是一个页面缓存条目,自从从数据库文件加载后缓存数据已被修改,因此不再匹配相应数据库文件页面的当前内容。脏页是当前正在缓冲作为写入事务的一部分对数据库文件所做的修改的页。
-
在本文档中,术语不可写的脏页专门用于指代具有修改内容的页面缓存条目,用于更新数据库文件尚不安全。根据第2.2.1节中的假设,如果在更新期间或之后不久发生的电源或系统故障可能导致数据库在系统恢复后损坏,则使用缓冲写入更新数据库文件是不安全的。
-
可以安全地使用修改后的内容更新相应的数据库文件页而不冒数据库损坏风险的脏页称为 可写脏页。
用于确定具有修改内容的页缓存条目是脏页还是可写页的确切逻辑在第4.2节中介绍。
因为主内存是一种有限的资源,页面缓存不能无限增长。因此,除非进程内的数据库连接打开的所有数据库文件都非常小,否则有时必须从页面缓存中丢弃数据。实际上,这意味着必须清除页面缓存条目以便为新条目腾出空间。如果从页面缓存中移除以释放主内存的页面缓存条目是脏页,则必须将其内容保存到数据库文件中,然后才能在不丢失数据的情况下将其丢弃。以下两个小节描述了页面缓存使用的算法以确定何时清除(丢弃) 现有页面缓存条目。
4.1. 页面缓存配置
描述设置页面缓存限制的参数。
4.2. 页面缓存算法
描述配置参数使用方式的要求。关于LRU等
5.读取数据
为了将数据从数据库返回给用户,例如作为 SELECT 查询的结果,SQLite 必须在某个时候从数据库文件中读取数据。通常,数据以页大小字节的对齐块从数据库文件中读取。例外情况是在检查数据库文件头字段时,在 知道数据库使用 的页面大小之前。
除了两个例外,数据库连接必须在数据库上有一个打开的事务(只读事务或 读/写事务),然后才能从数据库文件中读取数据。
两个例外是:
- 在打开数据库连接后立即尝试读取 100 字节的数据库文件头时 (请参阅第3.1节)。发生这种情况时,数据库文件上不会持有任何锁。
- 在打开只读事务的过程中读取的数据(请参阅第5.1节)。这些读取操作发生在数据库文件上持有 共享锁之后。
一旦事务打开,从数据库连接读取数据就是一个简单的操作。使用在数据库文件上打开的文件句柄的 xRead() 方法,一次读取所需的数据库文件页面。SQLite 从不读取部分页面,并且始终对每个需要的页面调用一次 xRead()。
读取数据库页面的数据后,SQLite 将原始数据页面存储在页面缓存中。每次上层需要一页数据时,都会查询页面缓存,看是否包含当前数据库连接存储的所需页面的副本。如果可以找到这样的条目,则将从页面缓存而不是数据库文件中读取所需的数据。只有与数据库上打开的事务(只读事务或 读/写事务)的连接才可以从页面缓存中读取数据 。从这个意义上说,从页面缓存中读取与从数据库文件中读取没有什么不同。
请参阅第4.2节,了解页面数据在 页面缓存中的确切存储方式和存储时间。
除了 H35070 要求的读操作和那些作为打开只读事务的一部分而进行的读操作外,SQLite在从数据库文件读取任何数据时应确保数据库连接具有打开的只读或读/写事务。
除了 H35070 和 H21XXX 描述的那些读取操作之外,SQLite 应该从数据库文件中以 页面大小字节的对齐块读取数据,其中页面大小是数据库文件使用的数据库页面大小。
在使用页面缓存中存储的数据满足用户查询 之前 ,SQLite 应确保数据库连接具有打开的只读或读/写事务。
5.1. 打开一个只读事务
在从数据库文件中读取数据或从页面缓存中查询数据之前,只读事务必须由关联的数据库连接成功打开(即使连接最终将写入数据库也是如此,作为 读/写事务只能通过从 只读事务升级来打开)。本节介绍打开只读事务的过程。
只读事务 的关键要素是在数据库文件上打开的文件句柄获取并持有数据库文件上的 共享锁。因为一个连接在实际修改数据库文件的内容之前需要一个独占锁,并且根据定义,当一个连接持有一个共享锁时,没有其他连接可以持有一个 独占锁,持有一个共享锁保证没有其他进程可能会在只读事务保持打开状态时修改数据库文件。这确保了只读事务与其他数据库用户的事务充分隔离(参见第1节)。
获取数据库文件本身的共享锁非常简单,SQLite 只需调用数据库文件句柄的 xLock() 方法即可。作为打开只读事务的一部分发生的其他一些过程非常复杂。SQLite 需要采取的步骤来打开一个只读事务,按照它们必须发生的顺序,如下所示:
- 在数据库文件上获得 共享锁。
- 该连接检查文件系统中是否存在热日志文件。如果有人这样做,那么它会在继续之前回滚。
- 连接检查页面缓存中的数据是否仍然可信。如果不是,则丢弃所有页面缓存数据。
- 如果文件大小不是零字节并且页面缓存不包含数据库第一页的有效数据,则必须从数据库读取第一页的数据。
当然,在尝试上面列举的 4 个步骤中的任何一个时都可能发生错误。如果发生这种情况,则释放共享锁(如果已获得)并向用户返回错误。上述过程的第 2 步在第 5.1.1节中有更详细的描述。第5.1.2节 描述了上面第 3 步确定的过程。有关步骤 4 的更多详细信息,请参见第5.1.3节。
当需要使用 数据库连接打开只读事务时,SQLite 应首先尝试在数据库文件上打开的文件句柄上 获取共享锁。
如果在打开只读事务时,SQLite 未能获得数据库文件上的共享锁,则该进程将被放弃,不会打开任何事务,并向用户返回一个错误。
尝试获取共享锁可能失败的最常见原因是某些其他连接持有独占锁或 挂起锁。然而,它也可能会失败,因为在调用 xLock() 方法时会发生一些其他错误(例如 IO 或通信相关错误)。
在打开只读事务时,在成功获得数据库文件的共享锁后,SQLite 将尝试检测并回滚与同一数据库文件关联 的热日志文件。
如果在打开只读事务时,SQLite 在尝试检测或回滚热日志文件时遇到错误,则会释放数据库文件上的共享锁,不会打开任何事务并将错误返回给用户。
第5.1.1节包含对上述要求中提到的热日志文件的检测的描述和要求。
假设没有发生错误,然后在尝试检测并回滚热日志文件后,如果页面缓存包含与当前数据库连接相关的任何条目,则 SQLite 将通过测试文件更改计数器来验证页面缓存的内容。此过程称为 缓存验证。
缓存验证过程在 5.1.2 节中有 详细描述
如果需要 H35040 规定的缓存验证过程,但不能证明与当前数据库连接关联的页面缓存条目有效,则 SQLite将从页面缓存中丢弃与当前数据库连接关联的所有条目。
上面的编号列表指出,数据库文件第一页的数据(如果存在并且尚未加载到页面缓存中)必须在只读事务被视为打开之前从数据库文件中读取。这由要求 H35240 处理。
5.1.1. 热点期刊检测
本节描述 SQLite 用于检测 热日志文件的过程。如果检测到热日志文件,这表明在某个时候将事务写入数据库的过程被中断,需要进行恢复操作(热日志回滚)。本节不描述热日志回滚过程(参见第 7.1节)或 创建热日志文件的过程(参见第 6节)。
用于检测热日志文件的过程非常复杂。发生以下步骤:
- 使用 VFS xAccess() 方法,SQLite 查询文件系统以查看与数据库关联的日志文件是否存在。如果没有,则没有hot-journal 文件。
- 通过调用在数据库文件上打开的文件句柄的 xCheckReservedLock() 方法,SQLite 检查其他连接是否持有保留锁或更大的锁。如果其他一些连接确实持有保留锁,这表明其他连接正在读/写事务的中途(请参阅第6节)。在这种情况下, 日志文件不是热日志,不能回滚。
- 使用在数据库文件上打开的文件句柄的 xFileSize() 方法,SQLite 检查数据库文件的大小是否为 0 字节。如果是,则该日志文件不被视为热日志文件。在这种情况下,不是回滚日志文件,而是通过调用 VFS xDelete() 方法将其从文件系统中删除。从技术上讲,这里存在竞争条件。这一步应该移到持有独占锁之后。
- 尝试升级到数据库文件上的独占锁。如果尝试失败,则所有锁,包括最近获得的共享锁都将被丢弃。打开只读事务的尝试失败。当一些其他连接也试图打开 只读事务并且尝试获得 独占锁失败时会发生这种情况,因为其他连接也持有共享锁。回滚热日志留给另一个连接。 在这种情况下,文件句柄锁直接从共享锁升级到独占锁很重要,而不是像获取独占锁写入数据库文件时所要求的那样首先升级到保留锁或挂起锁(第6节)。如果 SQLite 在这种情况下首先升级到保留锁或 挂起锁,那么第二个进程也试图在数据库文件上打开一个读事务可能会检测到保留锁锁定这个过程的第2步,断定没有hot journal,开始从数据库文件中读取数据。
- 再次调用 xAccess() 方法来检测日志文件是否仍在文件系统中。如果是,那么它就是一个热日志文件,SQLite 会尝试将其回滚(参见第 7节)。
主日志文件指针?
以下要求更详细地描述了上述过程的第 1 步。
当需要尝试检测热日志文件时,SQLite 应首先使用 VFS 层的 xAccess() 方法检查文件系统中是否存在日志文件。
如果 H35140 要求的对 xAccess() 的调用失败(由于 IO 错误或类似错误),则 SQLite 应放弃打开只读事务的尝试,放弃数据库文件上持有的共享锁并返回错误给用户。
当需要尝试检测热日志文件时,如果调用 H35140 要求的 xAccess() 指示日志文件不存在,则 SQLite 应断定文件系统中不存在热日志文件,因此不需要热日志回滚。
以下要求更详细地描述了上述过程的步骤 2。
当需要尝试检测hot-journal文件时,如果H35140要求的xAccess()调用表明存在journal文件,则调用数据库文件file-handle的xCheckReservedLock()方法判断是否存在某些其他进程持有数据库文件的保留锁或更大的锁。
如果 H35160 要求的 xCheckReservedLock() 调用失败(由于 IO 或其他内部 VFS 错误),则 SQLite 将放弃打开只读事务的尝试,放弃数据库文件上持有的共享锁 并返回错误给用户。
如果 H35160 要求的对 xCheckReservedLock() 的调用表明某些其他数据库连接持有数据库文件上的保留 锁或更大的锁,则 SQLite 应断定不存在热日志文件。在这种情况下,检测热日志文件的尝试结束。
以下要求更详细地描述了上述过程的步骤 3。
如果在尝试检测热日志文件时,对 xCheckReservedLock() 的调用表明没有进程持有数据库文件的保留 锁或更高锁,则 SQLite 将使用 VFS xOpen() 打开潜在热日志文件的文件句柄方法。
如果 H35440 要求的对 xOpen() 的调用失败(由于 IO 或其他内部 VFS 错误),则 SQLite 应放弃打开 只读事务的尝试,放弃数据库文件上持有的共享锁并返回错误给用户。
在成功打开潜在热日志文件的文件句柄后,SQLite 将使用打开文件句柄的 xFileSize() 方法查询文件的字节大小。
如果 H35450 要求的 xFileSize() 调用失败(由于 IO 或其他内部 VFS 错误),则 SQLite 将放弃打开只读事务的尝试,放弃数据库文件上持有的共享锁,关闭文件句柄在日志文件上打开并向用户返回错误。
如果 H35450 要求的查询显示潜在热日志文件的大小为零字节,则 SQLite 将关闭在日志文件上打开的文件句柄,并使用对 VFS xDelete() 方法的调用删除日志文件。在这种情况下,SQLite 将断定不存在热日志文件。
如果 H35450 要求的对 xDelete() 的调用失败(由于 IO 或其他内部 VFS 错误),则 SQLite 应放弃打开只读事务的尝试,放弃数据库文件上持有的共享锁并返回错误给用户。
以下要求更详细地描述了上述过程的第 4 步。
如果 H35450 要求的查询显示潜在热日志文件的大小大于零字节,则 SQLite 将尝试将数据库连接持有的 数据库文件上的共享锁直接升级为独占锁。
如果尝试升级到H35470 规定的独占锁由于任何原因失败,则 SQLite 将释放数据库连接持有的所有锁并关闭在日志文件上打开的文件句柄 。打开只读事务的尝试 应被视为失败并向用户返回错误。
最后,以下要求更详细地描述了上述过程的步骤 5。
如果作为热日志文件检测过程的一部分,尝试升级到 H35470 强制的独占锁成功,则 SQLite 应使用 VFS 实现的 xAccess() 方法查询文件系统以测试是否日志文件仍然存在于文件系统中。
如果 H35490 要求的对 xAccess() 的调用失败(由于 IO 或其他内部 VFS 错误),则 SQLite 应放弃打开只读事务的尝试,放弃对数据库文件的锁定,关闭文件句柄打开日志文件并向用户返回错误。
如果 H35490 要求的对 xAccess() 的调用显示文件系统中不再存在日志文件,则 SQLite 应放弃打开只读事务的尝试,放弃对数据库文件的锁定,关闭文件句柄在日志文件上打开并向用户返回 SQLITE_BUSY 错误。
如果 H35490 要求的 xAccess() 查询显示日志文件仍然存在于文件系统中,则 SQLite 将断定该日志文件是需要回滚的热日志文件。SQLite 应立即开始热日志回滚。
5.1.2. 缓存验证
当数据库连接打开读取事务时, 页面缓存可能已经包含与 数据库连接关联的数据。但是,如果另一个进程在加载缓存页面后修改了数据库文件,则缓存数据可能无效。
SQLite使用文件更改计数器(数据库文件头中的一个字段)确定属于数据库连接的页面缓存条目是否有效。文件更改计数器是一个 4 字节大端整数字段,存储在数据库文件头的 字节偏移量 24 处。在以任何方式修改数据库文件内容的读/写事务结束之前(参见第6节),存储在文件更改计数器中的值会递增。当一个数据库连接解锁数据库文件,它存储文件更改计数器的当前值。稍后,在打开一个新的只读事务时,SQLite 检查存储在数据库文件中的文件更改计数器的值。如果自从数据库文件解锁后该值没有改变,那么 可以信任页面缓存条目。如果该值已更改,则无法信任页面缓存条目,并且将丢弃 与当前数据库连接关联的所有条目。
当打开数据库文件的文件句柄被解锁时,如果 页面缓存包含一个或多个属于关联数据库连接的条目,SQLite 将在内部存储文件更改计数器的值。
当需要执行缓存验证作为打开读取事务的一部分时,SQLite 应使用数据库连接文件句柄 的 xRead() 方法从数据库文件的字节偏移量 24 开始读取一个 16 字节的块。
为什么是 16 字节块?为什么不是4?(与加密数据库有关)。
在执行缓存验证时,按照 H35190 的要求加载 16 字节块后,SQLite 应将存储在块的前 4 个字节中的 32 位大端整数与文件更改计数器的最近存储值进行比较(参见 H35180 ). 如果值不相同,则 SQLite 将得出缓存内容无效的结论。
要求 H35050(第5.1节)指定 SQLite 在确定缓存内容无效时需要采取的操作。
5.1.3. 第 1 页和预期的页面大小
作为对大小超过 0 字节的数据库文件打开读取事务 的最后一步,SQLite 需要将数据库第 1 页的数据加载到页面缓存中(如果尚未存在)。这比看起来稍微复杂一些,因为此时数据库页面大小未知。
即使无法确定数据库页面大小,SQLite 通常能够通过假设它等于连接预期页面大小来正确猜测。预期的页面大小 是打开数据库连接时从数据库文件头中读取 的页面大小字段的值(请参阅第3.1节),或者是结束 最多读取事务时数据库文件的页面大小。
在读取事务结束期间,在解锁数据库文件之前,SQLite 应将连接 预期页面大小设置为当前数据库页面大小。
作为打开新读取事务的一部分,在执行缓存验证后,如果页面缓存中没有数据库页面 1 的数据,SQLite 将使用连接的 xRead() 方法从数据库文件的开头读取N个字节文件句柄,其中N是连接当前 预期的页面大小值。
如果按照H35230的要求读取第1页数据,那么出现在数据库文件头中的 page-size字段的值消耗读取块的前100个字节与连接当前预期的页面大小不同,则预期的 页面大小设置为此值,数据库文件被解锁并 重复 打开读取事务的整个过程。
如果按照H35230的要求读取第1页数据,那么出现在数据库文件头中的 page-size字段的值消耗读取块的前100个字节与连接当前期望的页面大小相同,则读取的数据块作为第 1 页存储在页面缓存中。
5.2. 读取数据库数据
添加一些关于首先检查页面缓存等的内容。
5.3. 结束只读事务
要结束只读事务,SQLite 只需放弃 在数据库文件上打开的文件句柄上的共享锁。无需其他操作。
当需要结束只读事务时,SQLite 将通过调用文件句柄的 xUnlock() 方法放弃数据库文件上 的共享锁。
另见上述要求 H35180 和 H35210。
6.写入数据
使用 DDL 或 DML SQL 语句,SQLite 用户可以修改数据库文件的内容和大小。[3]中描述了如何将对逻辑数据库的更改准确地转换为对数据库文件的修改 。从本文档中描述的子系统的角度来看,执行的每个 DDL 或 DML 语句都会导致零个或多个数据库文件页面的内容被新数据覆盖。DDL 或 DML 语句还可以在数据库文件的末尾追加或截断一页或多页。一个或多个 DDL 和/或 DML 语句组合在一起构成单个写事务。写入事务需要具有部分中描述的特殊属性1 ; 写入事务必须是隔离的、持久的和原子的。
SQLite 使用以下技术实现这些目标:
为确保写事务是隔离的,在开始修改数据库文件的内容以反映写事务的结果之前,SQLite 获得数据库文件的独占锁。在写入事务结束之前,锁不会被放弃。因为从数据库文件中读取需要共享锁(请参阅第 5节)并且持有独占锁可以保证没有其他数据库连接持有或可以获得共享锁,这确保在部分应用 写事务时,没有其他连接可以从数据库文件读取数据。
确保写入事务是原子的是系统所需的最复杂的任务。在这种情况下,原子意味着即使发生系统故障,尝试向数据库文件提交写事务要么导致作为事务一部分的所有更改成功应用于数据库文件,要么没有任何更改被成功应用。不可能只应用更改的子集。因此,从外部观察者的角度来看,写入事务 似乎是一个原子事件。
当然,通常不可能将写入事务所需的所有更改原子地应用到文件系统中的数据库文件。例如,如果写事务 需要修改数据库文件的十页,而在sqlite仅修改了五页后停电导致系统故障,那么在系统恢复后数据库文件几乎肯定会处于不一致状态。
SQLite 通过使用日志文件解决了这个问题。在几乎所有情况下,在以任何方式修改数据库文件之前,SQLite 都会在日志文件中存储足够的信息,以便在更新数据库文件以反映所做的修改时发生系统故障时允许重建原始数据库文件通过写交易。每次 SQLite 打开一个数据库文件时,它会检查是否发生了这样的系统故障,如果是,则根据日志文件的内容重建数据库文件。用于检测此进程是否创建热日志回滚的程序, 需要在5.1.1节中描述。热日志回滚 本身在7.1节中描述。
同样的技术可以确保 SQLite 数据库文件不会被不合时宜的系统故障破坏。如果在 SQLite 有机会执行足够的同步文件操作以确保构成写入事务的更改已安全地进入持久存储之前发生系统故障,则日志文件将用于将数据库恢复到系统恢复后的已知良好状态。
为了使写入事务在系统故障时持久,SQLite在结束写入事务之前对数据库文件执行同步文件操作
页面缓存用于在 将修改写入数据库文件之前缓冲对数据库文件映像的修改。当写事务中的操作结果需要修改页面内容时,修改后的副本将存储在页面缓存中。同样,如果新页面附加到数据库文件的末尾,它们将被添加到页面缓存 中,而不是立即写入文件系统中的数据库文件。
理想情况下,整个写事务的所有更改都缓冲在页面缓存中,直到事务结束。当用户提交事务时,所有更改都将以最有效的方式应用到数据库文件,同时考虑第2.1节中列举的假设。不幸的是,由于主内存是一种有限的资源,这对于大型交易来说并不总是可行的。在这种情况下,更改会缓冲在页面缓存中,直到达到某些内部条件或限制,然后写出到数据库文件以便在需要时释放资源。第4.2节 描述在事务中将更改刷新到数据库文件以释放页面缓存资源的情况。
即使在 写入事务正在进行时没有发生应用程序或系统故障,也可能需要执行回滚操作以将数据库文件和页面缓存恢复到事务开始之前的状态。如果用户明确请求事务回滚(通过发出“ROLLBACK”命令),或者由于遇到 SQL 约束而自动请求事务回滚(请参阅 [2]),则可能会发生这种情况。因此,原始页面内容在页面缓存中被修改之前就存储在日志文件中。
介绍以下小节。
6.1. 日志文件格式
本节介绍 SQLite日志文件使用的格式。
一个日志文件由一个或多个日志标题、零个或多个日志记录以及可选的主日志指针组成。每个日志文件始终以 日志标题开头,后跟零个或多个日志记录。紧随其后的可能是第二个日志标题,然后是第二组零个或多个日志记录,依此类推。一个日志文件可以包含的日志标题的数量没有限制。在期刊标题及其随附的期刊记录集之后可能是可选的主日志指针。或者,文件可能只是在最终日志记录之后结束。
本节只描述日志文件的格式和构成它的各种对象。但是因为日志文件可能会在系统故障恢复后被 SQLite 进程读取(热日志回滚,请参阅第 7.1节),使用以下组合描述文件在文件系统中创建和填充的方式也很重要写文件、同步文件和 截断文件操作。这些在第 6.2节中描述。
6.1.1. 期刊标题格式
日志标头 的大小为扇区大小字节,其中 扇区大小是由在数据库文件上打开的文件句柄的 xSectorSize 方法返回的值。仅使用日志头的前 28 个字节,其余部分可能包含垃圾数据。每个日志头的前 28 个字节由一个设置为已知值的八字节块组成,后跟五个大端 32 位无符号整数字段。
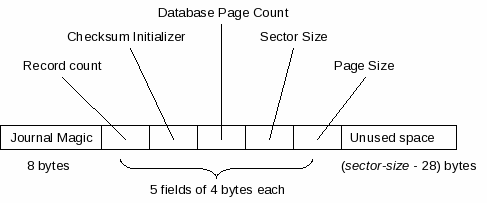
图2 - 期刊标题格式
图2以图形方式描述了日志页眉的布局。下表描述了各个字段。表的“字节偏移量”列中的偏移量是相对于日志标题的开始的。
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 8 | The journal magic field always contains a
well-known 8-byte string value used to identify SQLite
journal files. The well-known sequence of byte values
is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
| 8 | 4 | This field, the record count, is set to the number of journal records that follow this journal header in the journal file. |
| 12 | 4 | The checksum initializer field is set to a pseudo-random value. It is used as part of the algorithm to calculate the checksum for all journal records that follow this journal header. |
| 16 | 4 | This field, the database page count, is set to the number of pages that the database file contained before any modifications associated with write transaction are applied. |
| 20 | 4 | This field, the sector size, is set to the sector size of the device on which the journal file was created, in bytes. This value is required when reading the journal file to determine the size of each journal header. |
| 24 | 4 | The page size field contains the database page size used by the corresponding database file when the journal file was created, in bytes. |
所有日志标题都位于文件中,以便它们从扇区大小对齐的偏移量开始。为实现这一点,未使用的空间可能会留在第二个和后续 日志标题的开头 与与前一个标题相关联 的日志记录的结尾之间。
6.1.2. 日志记录格式
每个日志记录都包含由写入事务修改的数据库页面的原始数据。如果需要回滚,则此数据可用于将数据库页面的内容恢复到写事务开始之前的状态。

图3 - 日志记录格式
图3以图形方式描绘 的日志记录包含三个字段,如下表所述。字节偏移量是相对于 日志记录的开始的。
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | The page number of the database page associated with this journal record, stored as a 4 byte big-endian unsigned integer. |
| 4 | page-size | This field contains the original data for the page, exactly as it appeared in the database file before the write transaction began. |
| 4 + page-size | 4 | This field contains a checksum value, calculated based on the contents of the journaled database page data (the previous field) and the values stored in the checksum initializer field of the preceding journal header. |
日志文件 中日志标题后面的日志记录 集紧密地打包在一起。与日记帐标题一样 ,日记帐记录没有对齐要求。
6.1.3. 主日志指针
为了支持修改多个数据库文件的原子事务,SQLite 有时会在一个日志文件中包含一个主日志指针 记录。多文件事务在6.3节中描述。 主日志指针包含主日志文件 的名称以及校验和和一些众所周知的值,这些值允许在回滚操作期间读取 日志文件时识别主日志指针(第7节)。
与journal header的情况一样, master journal pointer的起点始终位于扇区大小 对齐的偏移量处。如果 紧接在主日志指针之前的日志记录或日志头没有以对齐的偏移量结束,则在日志记录或日志头的末尾与主日志指针的开始之间留下未使用的空间。
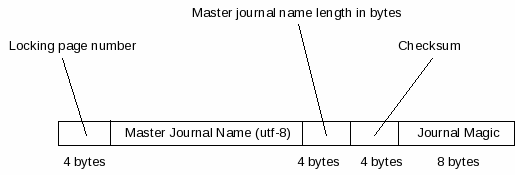
图4 - 主日志指针格式
图4以图形方式描绘 的主日志指针包含五个字段,如下表所述。字节偏移量是相对于主日志指针的开始。
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | This field, the locking page number, is always
set to the page number of the database locking page
stored as a 4-byte big-endian integer. The locking page
is the page that begins at byte offset 2 |
| 4 | name-length | The master journal name field contains the name of the master journal file, encoded as a utf-8 string. There is no nul-terminator appended to the string. |
| 4 + name-length | 4 | The name-length field contains the length of the previous field in bytes, formatted as a 4-byte big-endian unsigned integer. |
| 8 + name-length | 4 | The checksum field contains a checksum value stored as a 4-byte big-endian signed integer. The checksum value is calculated as the sum of the bytes that make up the master journal name field, interpreting each byte as an 8-bit signed integer. |
| 12 + name-length | 8 |
Finally, the journal magic field always contains a
well-known 8-byte string value; the same value stored in the
first 8 bytes of a journal header. The well-known
sequence of bytes is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
6.2. 写交易
本节描述 SQLite写事务的进程。从本文档中描述的系统的角度来看,大多数写入事务包括三个步骤:
写入事务打开。这个过程在第6.2.1节中描述。
最终用户执行需要修改数据库文件的数据库文件结构的DML或DDL SQL语句。这些修改可以是操作的任意组合
- 修改现有数据库页面的内容,
- 将新的数据库页面附加到数据库文件映像,或者
- 从数据库文件末尾截断(丢弃)数据库页面。
写入事务结束,所做的更改永久提交到数据库。提交事务所需的过程在第 6.2.5节中描述。
作为上述步骤 3 的替代方法,可以回滚事务。事务回滚在第7节中描述。最后,记住写入事务 可能随时被系统故障中断也很重要。在这种情况下,文件系统的内容(数据库文件和 日志文件)必须保持这样的状态,以使数据库文件能够恢复到中断的写入事务开始之前的状态。这称为热日志回滚,在第 7.1节中进行了描述. 2.2.1节 描述了关于系统故障对恢复后文件系统内容 的影响所做的假设。
6.2.1. 开始写入事务
在页面缓存中修改任何数据库页面之前,数据库连接必须打开一个写事务。打开写事务需要数据库连接获得数据库文件上的保留锁(或更大) 。因为获得数据库文件上的保留锁可以保证没有其他数据库连接可以持有或获得保留锁或更大的锁,因此没有其他数据库连接可以打开写交易。
数据库文件上的 保留锁可能被认为是日志文件上的独占锁。没有 相应数据库文件上的保留锁或更大锁, 任何数据库连接都不能读取或写入日志文件。
在打开写事务之前,数据库连接 必须有一个打开的读事务,通过第5.1节中描述的过程打开。这确保没有需要回滚的热日志文件,并且可以信任 存储在页面缓存中的任何数据。
一旦打开一个读事务,升级到一个 写事务是一个两步过程,如下所示:
- 在数据库文件上获得保留锁。
- 必要时打开并创建日志文件(使用VFS xOpen 方法),并使用对文件句柄 xWrite 方法的单个调用将日志文件头写入文件的开头。
详细描述上述程序步骤 1 的要求:
当需要在数据库上打开一个写事务时,SQLite 应该首先打开一个读事务,如果有问题的数据库连接还没有打开的话。
当需要在数据库上打开写事务时,在确保已打开读事务后,SQLite 将通过调用数据库文件上打开的文件句柄的 xLock 方法来获取数据库文件上的 保留锁。
如果尝试获取要求 H35360 规定的保留锁失败,则 SQLite 将认为打开写事务的尝试失败并向用户返回错误。
详细描述上述程序步骤 2 的要求:
当需要在数据库上打开写事务时,在获得数据库文件上的保留锁后,SQLite 将在相应的日志文件上打开一个读/写文件句柄。
当需要在数据库上打开写事务时,在打开日志文件的文件句柄后,SQLite 应将日志标头附加到(当前为空的)日志文件。
6.2.1.1. 写日记头
描述如何将日志标题附加到日志文件的要求:
当需要将日志标头附加到日志文件时,SQLite 应通过使用对日志文件 上打开的文件句柄的 xWrite 方法的单个调用来写入一个扇区大小的字节块。写入的数据块应从日志文件的当前末尾或之后的最小扇区大小对齐偏移量开始。
H35680 要求写入的日志头 的前 8 个字节应包含以下值,从字节偏移量 0 到 7 依次为:0xd9、0xd5、0x05、0xf9、0x20、0xa1、0x63 和 0xd7。
H35680要求写入 的journal header 的字节8-11应为0x00。
H35680 要求写入的日志头 的第 12-15 字节应包含当前写入事务开始时数据库文件包含的页数,格式为 4 字节大端无符号整数。
H35680 要求写入的日志头 的第 16-19 字节应包含伪随机生成的值。
H35680要求写入的journal header 的20-23字节应包含VFS层使用的扇区大小,格式为4字节big-endian无符号整数。
H35680 要求写入的日志头 的第 24-27 字节应包含数据库在写入事务开始时使用的页面大小,格式为 4 字节大端无符号整数。
6.2.2. 修改、添加或截断数据库页面
当最终用户执行 DML 或 DDL SQL 语句修改数据库模式或内容时,SQLite 需要更新数据库文件映像以反映新的数据库状态。这涉及修改、附加或截断多个数据库文件页面之一的内容。不是直接使用 VFS 接口修改数据库文件,而是首先在页面缓存中缓冲更改。
在修改可能需要通过回滚操作恢复 的页面缓存中的数据库页面之前,必须记录该页面。记录页面是将该页面的原始数据复制到日志文件中的过程,以便在写事务回滚时可以恢复它。记录页面的过程在第 6.2.2.1节中描述。
当需要修改现有数据库页面的内容时,该数据库页面存在并且在打开写事务时不是空闲列表叶页面,如果该页面尚未在当前写事务中记录,则 SQLite 将记录该页面。
当需要修改现有数据库页面的内容时,SQLite 应更新数据库页面内容的缓存版本,该版本存储为与页面关联 的页面缓存条目的一部分。
当一个新的数据库页面附加到数据库文件时,不需要向日志文件添加记录。如果需要回滚,数据库文件将根据存储在日志文件的字节偏移量 12 处的值简单地被截断回其原始大小。
当需要向数据库文件追加一个新的数据库页面时,SQLite 将创建一个新的页面缓存条目对应于新页面并将其插入到页面缓存中。应设置 新页面缓存条目的脏标志。
如果需要从数据库文件的末尾截断数据库页面,则会丢弃关联的页面缓存条目。调整后的数据库文件大小存储在内部。直到提交当前写入事务 (参见第6.2.5节),数据库文件才真正被截断。
当从数据库文件的末尾打开写入事务时, 如果需要截断(删除)存在的数据库页面并且不是空闲列表叶页面,SQLite 将记录该页面(如果它尚未在当前页面中记录)写交易。
当需要从数据库文件末尾截断数据库页面时,SQLite 应从页面缓存中丢弃相关的页面缓存条目 。
6.2.2.1. 记录数据库页面
通过向 日志文件添加日志记录来记录页面。日志记录的格式在第6.1.2节中描述。
当需要记录数据库页面时,SQLite 应首先将被记录页面的页码附加到 日志文件,格式为 4 字节大端无符号整数,使用对文件句柄的 xWrite 方法的单个调用在日志文件上打开。
当需要记录数据库页面时,如果尝试将页码附加到日志文件成功,则当前页面数据(页面大小字节)应附加到日志文件,使用对 xWrite 方法的单个调用在日志文件上打开的文件句柄。
当需要记录数据库页面时,如果尝试将当前页面数据附加到日志文件成功,则 SQLite 应将 4 字节大端整数校验和值附加到日志文件,使用一次调用在日志文件上打开的文件句柄的 xWrite 方法。
在页面数据之后立即写入日志文件的校验和值(要求 H35290)是页面数据和存储在 日志头中的校验和初始化字段的函数(参见第6.1.1节)。具体来说,它是校验和初始值与解释为 8 位无符号整数的每 200 个页面数据字节的值之和,从页面数据的第 ( page-size % 200) 个字节开始。例如,如果页面大小是 1024 字节,然后通过将偏移量 23、223、423、623、823 和 1023(页面的最后一个字节)处的字节值与校验和初始化程序的值相加来计算校验和。
H35290 要求写入日志文件 的校验和值应等于日志头(H35700)中存储的校验和初始化字段与页面数据的每 200 个字节的总和,以 ( page-size %第 200 个字节。
“%”字符在要求 H35300 中用于表示模运算符,就像在 C、Java 和 Javascript 等编程语言中一样。
6.2.3. 同步日志文件
即使在使用对日志文件文件句柄 xWrite 方法的调用(第6.2.2.1节) 将数据库页面的原始数据写入日志文件后,写入数据库文件中的页面仍然不安全。这是因为在系统故障的情况下,写入日志文件的数据可能仍会损坏(请参阅第2.2节)。在页面可以在数据库本身内更新之前,将发生以下过程:
- 调用在日志文件上打开的文件句柄的 xSync 方法。此操作可确保日志文件中的所有日志记录 都已写入持久存储,并且它们不会因后续系统故障而损坏。
- 日志文件中最近写入的日志头的日志记录计数字段(参见第 6.1.1节)被更新为包含自写入头以来添加到日志文件 的日志记录数。
- 再次调用 xSync 方法,以确保对日志记录计数的更新已提交到持久存储。
如果上面列举的所有三个步骤都成功执行,那么在数据库文件本身中修改日志 数据库页面 的内容是安全的。以上三个步骤的组合称为同步日志文件。
当需要同步日志文件时,SQLite 将调用在日志文件上打开的文件句柄的 xSync 方法。
当需要同步journal文件时,在调用H35750要求的xSync方法后,SQLite会更新最近写入 journal文件的journal header的记录数。应更新 4 字节字段以包含自写入日志头以来已写入 日志文件的日志记录数,格式为 4 字节大端无符号整数。
当需要同步日志文件时,在按照 H35760 的要求更新 日志头的记录计数字段后,SQLite 将调用日志文件上打开的文件句柄的 xSync 方法。
6.2.4. 升级到独占锁
在将页面缓存中修改的页面内容写入数据库文件之前,必须对数据库文件持有独占锁。此锁的目的是防止另一个连接在第一个连接写入数据库文件的中途时从数据库文件中读取。无论写入数据库文件的原因是因为正在提交事务,还是为了释放页面缓存中的空间,升级到 独占锁总是在同步日志文件后立即发生 。
当作为写入事务的一部分需要升级到独占锁时,SQLite 应首先尝试获取数据库文件上的挂起锁 (如果尚未通过调用在数据库文件上打开的文件句柄的 xLock 方法持有) 。
当作为写入事务的一部分 需要升级到独占锁时,在成功获得挂起锁后,SQLite 应尝试通过调用在数据库文件上打开的文件句柄的 xLock 方法来获得独占锁。
如果获取不到独占锁怎么办?从保留锁升级到挂起锁的尝试不可能失败。
6.2.5. 提交交易
提交写事务是更新数据库文件的最后一步。提交交易是一个七步过程,总结如下:
日志文件 已同步。同步日志文件所需的步骤在第 6.2.3节中描述。
如果尚未持有排他锁,请 升级到数据库文件的 排他锁。升级到 独占锁在第 6.2.4节中描述。
将页面缓存中存储 的所有脏页的内容复制到数据库文件中。为了提高性能,将脏页集按页码顺序写入数据库文件(详见2.1节中的假设 )。
同步数据库文件以确保所有更新都安全地存储在持久性媒体上。
关闭在日志文件 上打开的文件句柄,并删除日志文件本身。此时write transaction 事务已经不可撤销地提交。
数据库文件已解锁。
扩展并解释以上内容。
以下要求更详细地描述了上面列举的步骤。
当需要提交写事务时,SQLite 应修改第 1 页以增加存储在数据库文件头的更改计数器 字段中的值。
更改计数器是一个 4 字节大端整数字段,存储在数据库文件 的字节偏移量 24 处。H35800 要求的对第 1 页的修改是使用第 6.2.2节中描述的过程进行的。如果第 1 页尚未作为当前写入事务的一部分进行日志记录,则递增更改计数器可能需要对第 1 页进行日志记录。在所有情况下,对应于页面 1 的页面缓存条目都会成为脏页面,作为递增更改计数器值的一部分。
当需要提交写事务时,在增加更改计数器字段后,SQLite 应同步日志文件。
当需要提交写事务时,在按照 H35810 的要求同步日志文件后,如果 尚未持有数据库文件 的独占锁,则 SQLite 应尝试升级到独占锁。
当需要提交写事务时,在按照 H35810 的要求同步日志文件并确保按照 H35830 的 要求对数据库文件持有独占锁后,SQLite 会将页面缓存 中存储的所有脏页的内容复制到数据库文件使用调用数据库连接文件句柄的xWrite 方法。每次调用 xWrite 都应将单个 脏页的内容(页面大小字节的数据)写入数据库文件。脏页应按照页码从低到高的顺序写入。
当需要提交写事务时,在按照 H35830 的要求将任何脏页的内容复制到数据库文件后,SQLite 将通过调用数据库连接文件句柄 的 xSync 方法来同步数据库文件。
当需要提交写事务时,在按照 H35840 的要求同步数据库文件后,SQLite 应关闭在日志文件上打开的文件句柄,并通过调用 VFS xDelete 方法从文件系统中 删除 日志文件。
当需要提交写事务时,在按照 H35850 的要求删除日志文件后,SQLite 应通过调用数据库连接文件句柄 的 xUnlock 方法放弃数据库文件上的所有锁。
提交写事务后是否持有共享锁?
6.2.6. 清除脏页
通常,在用户提交活动写事务 之前,没有数据实际写入数据库文件。例外情况是单个写事务包含太多修改而无法存储在页面缓存中。在这种情况下,存储在页面缓存中的一些数据库文件修改必须在提交事务之前应用到数据库文件,以便可以从页面缓存中清除相关的页面缓存条目以释放内存。4.2节中描述了何时达到此条件并且必须清除脏页 。
在页面缓存项的内容可以写入数据库文件之前,页面缓存项必须满足可写脏页的条件,如4.2节中所定义 。如果脏页被4.2节的算法选中清除,则需要SQLite同步日志文件。日志文件同步后,所有与 数据库连接关联的脏页都被归类为可写脏页。
当需要从 页面缓存中清除不可写的脏页时,SQLite 将在继续执行 H35670 要求的写操作之前 同步日志文件。
按照 H35640 的要求同步日志文件 后,SQLite 将 在继续进行 H35670 要求的写操作之前 向日志文件附加一个新的日志头。
在6.2.1.1节中描述了向日志文件 附加一个新的日志头。
一旦被清除的脏页是可写的,它就被简单地写入数据库文件。
当需要清除作为脏页的页面缓存条目时, SQLite 应将页面数据写入数据库文件,使用对数据库连接文件句柄的 xWrite 方法的单个调用。
6.3. 多文件交易
6.4. 报表交易
7.回滚
7.1. 热日志回滚
7.2. 事务回滚
7.3. 语句回滚
8.参考资料
| [1] | C API Requirements Document. |
| [2] | SQL Requirements Document. |
| [3] | File Format Requirements Document. |