概述
FTS3 和 FTS4 是 SQLite 虚拟表模块,允许用户对一组文档执行全文搜索。描述全文搜索的最常见(也是最有效)的方式是“Google、Yahoo 和 Bing 对万维网上的文档所做的”。用户输入一个术语或一系列术语,可能由二元运算符连接或组合成一个短语,全文查询系统会根据用户指定的运算符和分组找到与这些术语最匹配的文档集。本文介绍FTS3和FTS4的部署和使用。
FTS1 和 FTS2 是 SQLite 的过时全文搜索模块。这些旧模块存在已知问题,应避免使用它们。部分原始 FTS3 代码由Google的 Scott Hess 贡献给 SQLite 项目。它现在作为 SQLite 的一部分进行开发和维护。
一、FTS3和FTS4介绍
FTS3 和 FTS4 扩展模块允许用户创建具有内置全文索引的特殊表(以下简称“FTS 表”)。全文索引允许用户高效地查询数据库中包含一个或多个单词(以下简称“标记”)的所有行,即使表中包含许多大型文档。
例如,如果将“ Enron E-Mail Dataset ”中的 517430 个文档分别插入到 FTS 表和使用以下 SQL 脚本创建的普通 SQLite 表中:
CREATE VIRTUAL TABLE enrondata1 USING fts3(content TEXT); /* FTS3 table */ CREATE TABLE enrondata2(content TEXT); /* Ordinary table */
然后可以执行以下两个查询中的任何一个来查找数据库中包含单词“linux”的文档数 (351)。使用一台台式 PC 硬件配置,对 FTS3 表的查询返回时间约为 0.03 秒,而查询普通表的时间为 22.5 秒。
SELECT count(*) FROM enrondata1 WHERE content MATCH 'linux'; /* 0.03 seconds */ SELECT count(*) FROM enrondata2 WHERE content LIKE '%linux%'; /* 22.5 seconds */
当然,上面的两个查询并不完全等价。例如,LIKE 查询匹配包含“linuxophobe”或“EnterpriseLinux”等术语的行(碰巧,Enron 电子邮件数据集实际上不包含任何此类术语),而 FTS3 表上的 MATCH 查询仅选择那些包含“linux”作为离散标记的行。两种搜索都不区分大小写。FTS3 表在磁盘上占用大约 2006 MB,而普通表仅占用 1453 MB。使用用于执行上述 SELECT 查询的相同硬件配置,FTS3 表的填充时间不到 31 分钟,而普通表为 25 分钟。
1.1. FTS3 和 FTS4 之间的差异
FTS3 和 FTS4 几乎相同。它们共享大部分代码,并且它们的界面相同。不同之处在于:
-
FTS4 包含查询性能优化,可以显着提高包含非常常见的术语(存在于大部分表行中)的全文查询的性能。
-
FTS4 支持一些可以与matchinfo() 函数一起使用的附加选项。
-
因为它在两个新的 影子表中存储磁盘上的额外信息以支持性能优化和额外的 matchinfo() 选项,所以 FTS4 表可能比使用 FTS3 创建的等效表消耗更多的磁盘空间。通常开销为 1-2% 或更少,但如果 FTS 表中存储的文档非常小,开销可能高达 10%。通过将指令“matchinfo=fts3”指定为 FTS4 表声明的一部分,可以减少开销,但这是以牺牲一些额外支持的 matchinfo() 选项为代价的。
-
FTS4 提供挂钩(压缩和解压缩 选项)允许数据以压缩形式存储,减少磁盘使用和 IO。
FTS4 是对 FTS3 的增强。FTS3 自 SQLite版本 3.5.0 (2007-09-04) 以来可用 FTS4 的增强功能已添加到 SQLite版本 3.7.4 (2010-12-07)。
您应该在您的应用程序中使用哪个模块,FTS3 或 FTS4?FTS4 有时比 FTS3 快得多,甚至快几个数量级,具体取决于查询,尽管在常见情况下这两个模块的性能相似。FTS4 还提供增强的matchinfo()输出,可用于对MATCH操作的结果进行排名。另一方面,在没有matchinfo=fts3指令的情况下,FTS4 需要比 FTS3 多一点的磁盘空间,尽管在大多数情况下仅为百分之二。
对于较新的应用程序,建议使用 FTS4;尽管如果与旧版本的 SQLite 的兼容性很重要,那么 FTS3 通常也可以提供同样的服务。
1.2. 创建和销毁 FTS 表
与其他虚拟表类型一样,新的 FTS 表是使用 CREATE VIRTUAL TABLE语句创建的。跟在 USING 关键字后面的模块名称是“fts3”或“fts4”。虚拟表模块参数可以留空,在这种情况下,将创建一个带有名为“content”的单个用户定义列的 FTS 表。或者,可以向模块参数传递一个逗号分隔的列名列表。
如果作为 CREATE VIRTUAL TABLE 语句的一部分为 FTS 表显式提供列名,则可以选择为每个列指定数据类型名称。这是纯粹的语法糖,提供的类型名称不被 FTS 或 SQLite 核心用于任何目的。这同样适用于与 FTS 列名称一起指定的任何约束 - 它们被解析但不被系统以任何方式使用或记录。
-- Create an FTS table named "data" with one column - "content": CREATE VIRTUAL TABLE data USING fts3(); -- Create an FTS table named "pages" with three columns: CREATE VIRTUAL TABLE pages USING fts4(title, keywords, body); -- Create an FTS table named "mail" with two columns. Datatypes -- and column constraints are specified along with each column. These -- are completely ignored by FTS and SQLite. CREATE VIRTUAL TABLE mail USING fts3( subject VARCHAR(256) NOT NULL, body TEXT CHECK(length(body)<10240) );
除了列列表外,传递给用于创建 FTS 表的 CREATE VIRTUAL TABLE 语句的模块参数可用于指定标记器。这是通过指定“tokenize=<tokenizer name> <tokenizer args>”形式的字符串来代替列名来完成的,其中 <tokenizer name> 是要使用的 tokenizer 的名称,<tokenizer args> 是可选的传递给 tokenizer 实现的以空格分隔的限定符列表。分词器规范可以放在列列表中的任何位置,但每个 CREATE VIRTUAL TABLE 语句最多允许一个分词器声明。有关使用(并在必要时实施)分词器的详细说明, 请参见下文。
-- Create an FTS table named "papers" with two columns that uses -- the tokenizer "porter". CREATE VIRTUAL TABLE papers USING fts3(author, document, tokenize=porter); -- Create an FTS table with a single column - "content" - that uses -- the "simple" tokenizer. CREATE VIRTUAL TABLE data USING fts4(tokenize=simple); -- Create an FTS table with two columns that uses the "icu" tokenizer. -- The qualifier "en_AU" is passed to the tokenizer implementation CREATE VIRTUAL TABLE names USING fts3(a, b, tokenize=icu en_AU);
可以使用普通的DROP TABLE 语句从数据库中删除 FTS 表。例如:
-- Create, then immediately drop, an FTS4 table. CREATE VIRTUAL TABLE data USING fts4(); DROP TABLE data;
1.3. 填充 FTS 表
FTS 表以 与普通 SQLite 表相同的方式 使用INSERT、UPDATE和DELETE语句填充。
除了用户命名的列(如果没有模块参数被指定为CREATE VIRTUAL TABLE 语句的一部分,则为“content”列),每个 FTS 表都有一个“rowid”列。FTS 表的 rowid 与普通 SQLite 表的 rowid 列的行为方式相同,只是如果使用VACUUM命令重建数据库,FTS 表的 rowid 列中存储的值保持不变。对于 FTS 表,“docid”可以作为别名以及通常的“rowid”、“oid”和“_oid_”标识符。尝试使用表中已存在的 docid 值插入或更新行是错误的,就像使用普通 SQLite 表一样。
“docid”和 rowid 列的普通 SQLite 别名之间还有一个细微差别。通常,如果 INSERT 或 UPDATE 语句将离散值分配给 rowid 列的两个或多个别名,SQLite 会将 INSERT 或 UPDATE 语句中指定的此类值的最右边写入数据库。但是,在插入或更新 FTS 表时,将非 NULL 值分配给“docid”和一个或多个 SQLite rowid 别名将被视为错误。请参阅下面的示例。
-- Create an FTS table
CREATE VIRTUAL TABLE pages USING fts4(title, body);
-- Insert a row with a specific docid value.
INSERT INTO pages(docid, title, body) VALUES(53, 'Home Page', 'SQLite is a software...');
-- Insert a row and allow FTS to assign a docid value using the same algorithm as
-- SQLite uses for ordinary tables. In this case the new docid will be 54,
-- one greater than the largest docid currently present in the table.
INSERT INTO pages(title, body) VALUES('Download', 'All SQLite source code...');
-- Change the title of the row just inserted.
UPDATE pages SET title = 'Download SQLite' WHERE rowid = 54;
-- Delete the entire table contents.
DELETE FROM pages;
-- The following is an error. It is not possible to assign non-NULL values to both
-- the rowid and docid columns of an FTS table.
INSERT INTO pages(rowid, docid, title, body) VALUES(1, 2, 'A title', 'A document body');
为了支持全文查询,FTS 维护了一个倒排索引,该索引从数据集中出现的每个唯一术语或单词映射到它在表内容中出现的位置。出于好奇,下面显示了用于在数据库文件中存储该索引的数据结构的完整描述。这种数据结构的一个特点是,在任何时候,数据库可能包含的不是一个索引 b 树,而是几个不同的 b 树,它们随着行的插入、更新和删除而逐渐合并。这种技术在写入 FTS 表时提高了性能,但会导致使用索引的全文查询产生一些开销。评估特殊的“优化”命令,形式为“INSERT INTO <fts-table>(<fts-table>) VALUES('optimize')”的 SQL 语句导致 FTS 将所有现有索引 b 树合并为一个包含整个索引的大 b 树指数。这可能是一项昂贵的操作,但可能会加快未来的查询速度。
例如,要优化名为“docs”的 FTS 表的全文索引:
-- Optimize the internal structure of FTS table "docs".
INSERT INTO docs(docs) VALUES('optimize');
上面的陈述在某些人看来可能在句法上不正确。有关解释,请参阅描述简单 fts 查询的部分。
还有另一种已弃用的方法,用于使用 SELECT 语句调用优化操作。新代码应使用类似于上述 INSERT 的语句来优化 FTS 结构。
1.4. 简单的 FTS 查询
对于所有其他 SQLite 表,无论是虚拟表还是其他表,都使用SELECT语句从 FTS 表中检索数据。
可以使用两种不同形式的 SELECT 语句高效地查询 FTS 表:
按 rowid 查询。如果 SELECT 语句的 WHERE 子句包含形式为“rowid = ?”的子句,其中?是一个 SQL 表达式,FTS 能够使用 SQLite INTEGER PRIMARY KEY索引的等价物直接检索请求的行。
全文查询。如果 SELECT 语句的 WHERE 子句包含“<column> MATCH ?”形式的子句,FTS 能够使用内置的全文索引将搜索限制为与全文匹配的那些文档指定为 MATCH 子句右侧操作数的查询字符串。
如果这两种查询策略都不能使用,则所有对FTS表的查询都使用全表线性扫描来实现。如果表包含大量数据,这可能是一种不切实际的方法(本页的第一个示例显示使用现代 PC 线性扫描 1.5 GB 数据大约需要 30 秒)。
-- The examples in this block assume the following FTS table: CREATE VIRTUAL TABLE mail USING fts3(subject, body); SELECT * FROM mail WHERE rowid = 15; -- Fast. Rowid lookup. SELECT * FROM mail WHERE body MATCH 'sqlite'; -- Fast. Full-text query. SELECT * FROM mail WHERE mail MATCH 'search'; -- Fast. Full-text query. SELECT * FROM mail WHERE rowid BETWEEN 15 AND 20; -- Fast. Rowid lookup. SELECT * FROM mail WHERE subject = 'database'; -- Slow. Linear scan. SELECT * FROM mail WHERE subject MATCH 'database'; -- Fast. Full-text query.
在上面的所有全文查询中,MATCH 运算符的右侧操作数是一个由单个术语组成的字符串。在这种情况下,对于包含指定单词(“sqlite”、“搜索”或“数据库”,具体取决于您查看的示例)的一个或多个实例的所有文档,MATCH 表达式的计算结果为真。将单个术语指定为 MATCH 运算符的右侧操作数会导致最简单和最常见的全文查询类型。然而,更复杂的查询是可能的,包括短语搜索、术语前缀搜索和搜索包含在彼此定义的邻近范围内出现的术语组合的文档。下面介绍了查询全文索引的各种方式 。
通常,全文查询不区分大小写。但是,这取决于被查询的 FTS 表使用的特定分词器。有关详细信息,请参阅标记器部分。
上面的段落指出,对于包含指定术语的所有文档,将简单术语作为右侧操作数的 MATCH 运算符的计算结果为真。在此上下文中,“文档”可以指存储在 FTS 表的一行的单个列中的数据,也可以指单个行中所有列的内容,具体取决于用作左侧操作数的标识符给 MATCH 运算符。如果指定为 MATCH 运算符左侧操作数的标识符是 FTS 表列名,则必须包含搜索词的文档是存储在指定列中的值。但是,如果标识符是 FTS表的名称本身,则 MATCH 运算符对 FTS 表中任何列包含搜索词的每一行的计算结果为真。以下示例演示了这一点:
-- Example schema CREATE VIRTUAL TABLE mail USING fts3(subject, body); -- Example table population INSERT INTO mail(docid, subject, body) VALUES(1, 'software feedback', 'found it too slow'); INSERT INTO mail(docid, subject, body) VALUES(2, 'software feedback', 'no feedback'); INSERT INTO mail(docid, subject, body) VALUES(3, 'slow lunch order', 'was a software problem'); -- Example queries SELECT * FROM mail WHERE subject MATCH 'software'; -- Selects rows 1 and 2 SELECT * FROM mail WHERE body MATCH 'feedback'; -- Selects row 2 SELECT * FROM mail WHERE mail MATCH 'software'; -- Selects rows 1, 2 and 3 SELECT * FROM mail WHERE mail MATCH 'slow'; -- Selects rows 1 and 3
乍一看,上面示例中的最后两个全文查询在语法上似乎不正确,因为有一个表名(“mail”)用作 SQL 表达式。这是可以接受的原因是每个 FTS 表实际上都有一个与表本身同名的隐藏列(在本例中为“邮件”)。此列中存储的值对应用程序没有意义,但可以用作 MATCH 运算符的左侧操作数。这个特殊的列也可以作为参数传递给FTS 辅助函数。
下面的例子说明了上面的内容。表达式“docs”、“docs.docs”和“main.docs.docs”都指的是列“docs”。但是,表达式“main.docs”并未引用任何列。它可以用来指代一个表,但在下面使用它的上下文中不允许使用表名。
-- Example schema CREATE VIRTUAL TABLE docs USING fts4(content); -- Example queries SELECT * FROM docs WHERE docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE docs.docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE main.docs.docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE main.docs MATCH 'sqlite'; -- Error.
1.5. 概括
从用户的角度来看,FTS 表在很多方面都类似于普通的 SQLite 表。可以使用 INSERT、UPDATE 和 DELETE 命令在 FTS 表中添加、修改和删除数据,就像在普通表中一样。类似地,SELECT 命令可用于查询数据。以下列表总结了 FTS 与普通表的区别:
对于所有虚拟表类型,不可能创建附加到 FTS 表的索引或触发器。也不可能使用 ALTER TABLE 命令向 FTS 表添加额外的列(尽管可以使用 ALTER TABLE 重命名 FTS 表)。
在用于创建 FTS 表的“CREATE VIRTUAL TABLE”语句中指定的数据类型将被完全忽略。与将类型关联应用于插入值的常规规则不同,插入到 FTS 表列(特殊 rowid 列除外)的所有值在存储之前都转换为 TEXT 类型。
FTS 表允许使用特殊别名“docid”来引用所有虚拟表支持的 rowid 列。
基于内置全文索引的查询支持 FTS MATCH 运算 符。
FTS 辅助函数snippet()、offsets ( )和matchinfo()可用于支持全文查询。
每个 FTS 表都有一个与表本身同名的隐藏列。隐藏列的每一行中包含的值是一个 blob,它仅用作 MATCH运算符的左操作数,或用作FTS 辅助函数之一的最左边的参数。
2.编译并启用FTS3和FTS4
尽管 FTS3 和 FTS4 包含在 SQLite 核心源代码中,但默认情况下它们未启用。要构建启用了 FTS 功能的 SQLite,请在编译时定义预处理器宏SQLITE_ENABLE_FTS3。新的应用程序还应该定义SQLITE_ENABLE_FTS3_PARENTHESIS宏以启用 增强的查询语法(见下文)。通常,这是通过将以下两个开关添加到编译器命令行来完成的:
-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS
请注意,启用 FTS3 也会使 FTS4 可用。没有单独的 SQLITE_ENABLE_FTS4 编译时选项。SQLite 的构建要么同时支持 FTS3 和 FTS4,要么两者都不支持。
如果使用基于合并 autoconf 的构建系统,在运行“configure”脚本时设置 CPPFLAGS 环境变量是设置这些宏的简单方法。例如,以下命令:
CPPFLAGS="-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS" ./configure <configure options>
其中<configure options>是那些通常传递给配置脚本的选项,如果有的话。
因为 FTS3 和 FTS4 是虚拟表,所以SQLITE_ENABLE_FTS3编译时选项与SQLITE_OMIT_VIRTUALTABLE选项不兼容。
如果 SQLite 的构建不包含 FTS 模块,则任何准备 SQL 语句以创建 FTS3 或 FTS4 表或以任何方式删除或访问现有 FTS 表的尝试都将失败。返回的错误消息类似于“没有这样的模块:ftsN”(其中 N 是 3 或 4)。
如果ICU 库 的 C 版本 可用,则 FTS 也可以使用定义的 SQLITE_ENABLE_ICU 预处理器宏进行编译。使用此宏进行编译可启用 FTS 标记器,该标记器使用 ICU 库使用指定语言和区域设置的约定将文档拆分为术语(单词)。
-DSQLITE_ENABLE_ICU
3、全文索引查询
FTS 表最有用的地方是可以使用内置的全文索引执行的查询。全文查询是通过将格式为“<column> MATCH <full-text query expression>”的子句指定为从 FTS 表读取数据的 SELECT 语句的 WHERE 子句的一部分来执行的。 上面描述了返回包含给定术语的所有文档的简单 FTS 查询。在该讨论中,假设 MATCH 运算符的右侧操作数是由单个项组成的字符串。本节介绍 FTS 表支持的更复杂的查询类型,以及如何通过将更复杂的查询表达式指定为 MATCH 运算符的右侧操作数来使用它们。
FTS 表支持三种基本查询类型:
令牌或令牌前缀查询。可以查询 FTS 表以查找包含指定术语的所有文档(上述简单情况),或查询包含具有指定前缀的术语的所有文档。正如我们所见,特定术语的查询表达式就是术语本身。用于搜索术语前缀的查询表达式是前缀本身加上一个“*”字符。例如:
-- Virtual table declaration CREATE VIRTUAL TABLE docs USING fts3(title, body); -- Query for all documents containing the term "linux": SELECT * FROM docs WHERE docs MATCH 'linux'; -- Query for all documents containing a term with the prefix "lin". This will match -- all documents that contain "linux", but also those that contain terms "linear", --"linker", "linguistic" and so on. SELECT * FROM docs WHERE docs MATCH 'lin*';
通常,令牌或令牌前缀查询与指定为 MATCH 运算符左侧的 FTS 表列匹配。或者,如果指定了与 FTS 表本身同名的特殊列,则针对所有列。这可以通过在基本术语查询之前指定列名后跟“:”字符来覆盖。“:”和要查询的术语之间可能有空格,但列名和“:”字符之间没有空格。例如:
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "problems" appears in either the title
-- or body of the document.
SELECT * FROM docs WHERE docs MATCH 'title:linux problems';
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "driver" appears in the body of the document
-- ("driver" may also appear in the title, but this alone will not satisfy the
-- query criteria).
SELECT * FROM docs WHERE body MATCH 'title:linux driver';
如果 FTS 表是 FTS4 表(不是 FTS3),令牌也可以以“^”字符为前缀。在这种情况下,为了匹配标记必须作为匹配行的任何列中的第一个标记出现。例子:
-- All documents for which "linux" is the first token of at least one -- column. SELECT * FROM docs WHERE docs MATCH '^linux'; -- All documents for which the first token in column "title" begins with "lin". SELECT * FROM docs WHERE body MATCH 'title: ^lin*';
词组查询。短语查询是一种查询,它以指定的顺序检索包含一组指定的术语或术语前缀的所有文档,没有中间标记。短语查询是通过用双引号 (") 括起空格分隔的术语序列或术语前缀来指定的。例如:
-- Query for all documents that contain the phrase "linux applications". SELECT * FROM docs WHERE docs MATCH '"linux applications"'; -- Query for all documents that contain a phrase that matches "lin* app*". As well as -- "linux applications", this will match common phrases such as "linoleum appliances" -- or "link apprentice". SELECT * FROM docs WHERE docs MATCH '"lin* app*"';
近查询。NEAR 查询是一种返回文档的查询,这些文档包含两个或更多指定的术语或短语,它们在彼此指定的接近度内(默认情况下有 10 个或更少的中间术语)。NEAR 查询是通过在两个短语、令牌或令牌前缀查询之间放置关键字“NEAR”来指定的。要指定默认值以外的接近度,可以使用“NEAR/ <N> ”形式的运算符,其中 <N>是允许的中间项的最大数量。例如:
-- Virtual table declaration.
CREATE VIRTUAL TABLE docs USING fts4();
-- Virtual table data.
INSERT INTO docs VALUES('SQLite is an ACID compliant embedded relational database management system');
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 10 intervening terms. This matches the only document in
-- table docs (since there are only six terms between "SQLite" and "database"
-- in the document).
SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR database';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 6 intervening terms. This also matches the only document in
-- table docs. Note that the order in which the terms appear in the document
-- does not have to be the same as the order in which they appear in the query.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/6 sqlite';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 5 intervening terms. This query matches no documents.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/5 sqlite';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "database" with not more than 2 terms separating the two. This matches the
-- document stored in table docs.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/2 "ACID compliant"';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "sqlite" with not more than 2 terms separating the two. This also matches
-- the only document stored in table docs.
SELECT * FROM docs WHERE docs MATCH '"ACID compliant" NEAR/2 sqlite';
一个查询中可能出现多个 NEAR 运算符。在这种情况下,由 NEAR 运算符分隔的每对术语或短语必须出现在文档中彼此指定的邻近范围内。使用与上述示例块中相同的表和数据:
-- The following query selects documents that contains an instance of the term -- "sqlite" separated by two or fewer terms from an instance of the term "acid", -- which is in turn separated by two or fewer terms from an instance of the term -- "relational". SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR/2 acid NEAR/2 relational'; -- This query matches no documents. There is an instance of the term "sqlite" with -- sufficient proximity to an instance of "acid" but it is not sufficiently close -- to an instance of the term "relational". SELECT * FROM docs WHERE docs MATCH 'acid NEAR/2 sqlite NEAR/2 relational';
Phrase 和 NEAR 查询不能跨越一行中的多个列。
上述三种基本查询类型可用于查询全文索引以查找符合指定条件的文档集。使用 FTS 查询表达式语言,可以对基本查询的结果执行各种集合操作。目前支持三种操作:
- AND 运算符确定两组文档 的交集。
- OR 运算符计算两组文档 的并集。
- NOT 运算符(或者,如果使用标准语法,则为一元“-”运算符)可用于计算一组文档相对于另一组文档 的相对补码。
FTS 模块可以编译为使用全文查询语法的两个略有不同版本之一,即“标准”查询语法和“增强”查询语法。上面描述的基本术语、术语前缀、短语和 NEAR 查询在两个版本的语法中是相同的。指定集合操作的方式略有不同。以下两个小节描述了两个查询语法中与集合操作相关的部分。编译注意事项请参考如何编译fts的说明。
3.1. 使用增强的查询语法设置操作
增强的查询语法支持 AND、OR 和 NOT 二元集合运算符。运算符的两个操作数中的每一个都可以是基本的 FTS 查询,或者是另一个 AND、OR 或 NOT 设置运算的结果。运算符必须使用大写字母输入。否则,它们将被解释为基本术语查询而不是集合运算符。
可以隐式指定 AND 运算符。如果两个基本查询在 FTS 查询字符串中出现时没有运算符将它们分隔开,则结果与两个基本查询由 AND 运算符分隔时的结果相同。例如,查询表达式“隐式运算符”是“隐式 AND 运算符”的更简洁版本。
-- Virtual table declaration CREATE VIRTUAL TABLE docs USING fts3(); -- Virtual table data INSERT INTO docs(docid, content) VALUES(1, 'a database is a software system'); INSERT INTO docs(docid, content) VALUES(2, 'sqlite is a software system'); INSERT INTO docs(docid, content) VALUES(3, 'sqlite is a database'); -- Return the set of documents that contain the term "sqlite", and the -- term "database". This query will return the document with docid 3 only. SELECT * FROM docs WHERE docs MATCH 'sqlite AND database'; -- Again, return the set of documents that contain both "sqlite" and -- "database". This time, use an implicit AND operator. Again, document -- 3 is the only document matched by this query. SELECT * FROM docs WHERE docs MATCH 'database sqlite'; -- Query for the set of documents that contains either "sqlite" or "database". -- All three documents in the database are matched by this query. SELECT * FROM docs WHERE docs MATCH 'sqlite OR database'; -- Query for all documents that contain the term "database", but do not contain -- the term "sqlite". Document 1 is the only document that matches this criteria. SELECT * FROM docs WHERE docs MATCH 'database NOT sqlite'; -- The following query matches no documents. Because "and" is in lowercase letters, -- it is interpreted as a basic term query instead of an operator. Operators must -- be specified using capital letters. In practice, this query will match any documents -- that contain each of the three terms "database", "and" and "sqlite" at least once. -- No documents in the example data above match this criteria. SELECT * FROM docs WHERE docs MATCH 'database and sqlite';
上面的示例都使用基本的全文术语查询作为集合操作的两个操作数。也可以使用短语和 NEAR 查询,就像其他集合操作的结果一样。当 FTS 查询中存在多个集合操作时,操作符的优先级如下:
| Operator | Enhanced Query Syntax Precedence |
|---|---|
| NOT | Highest precedence (tightest grouping). |
| AND | |
| OR | Lowest precedence (loosest grouping). |
使用增强的查询语法时,可以使用括号来覆盖各种运算符的默认优先级。例如:
-- Return the docid values associated with all documents that contain the
-- two terms "sqlite" and "database", and/or contain the term "library".
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database OR library';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database'
UNION
SELECT docid FROM docs WHERE docs MATCH 'library';
-- Query for the set of documents that contains the term "linux", and at least
-- one of the phrases "sqlite database" and "sqlite library".
SELECT docid FROM docs WHERE docs MATCH '("sqlite database" OR "sqlite library") AND linux';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'linux'
INTERSECT
SELECT docid FROM (
SELECT docid FROM docs WHERE docs MATCH '"sqlite library"'
UNION
SELECT docid FROM docs WHERE docs MATCH '"sqlite database"'
);
3.2. 使用标准查询语法设置操作
使用标准查询语法的 FTS 查询集操作与使用增强查询语法的设置操作相似,但不完全相同。有四点不同,如下:
仅支持 AND 运算符的隐式版本。将字符串“AND”指定为标准查询语法查询的一部分被解释为对包含术语“and”的文档集的术语查询。
不支持括号。
不支持 NOT 运算符。标准查询语法支持一元“-”运算符,而不是 NOT 运算符,该运算符可应用于基本术语和术语前缀查询(但不适用于短语或 NEAR 查询)。附加有一元“-”运算符的术语或术语前缀可能不会作为 OR 运算符的操作数出现。FTS 查询可能不完全由带有一元“-”运算符的术语或术语前缀查询组成。
-- Search for the set of documents that contain the term "sqlite" but do -- not contain the term "database". SELECT * FROM docs WHERE docs MATCH 'sqlite -database';
集合操作的相对优先级是不同的。特别是,使用标准查询语法,“OR”运算符的优先级高于“AND”。使用标准查询语法时运算符的优先级是:
| Operator | Standard Query Syntax Precedence |
|---|---|
| Unary "-" | Highest precedence (tightest grouping). |
| OR | |
| AND | Lowest precedence (loosest grouping). |
- 以下示例说明了使用标准查询语法的运算符的优先级:
-- Search for documents that contain at least one of the terms "database" -- and "sqlite", and also contain the term "library". Because of the differences -- in operator precedences, this query would have a different interpretation using -- the enhanced query syntax. SELECT * FROM docs WHERE docs MATCH 'sqlite OR database library';
4.辅助功能——Snippet、Offsets和Matchinfo
FTS3 和 FTS4 模块提供了三个可能对全文查询系统开发人员有用的特殊 SQL 标量函数:“snippet”、“offsets”和“matchinfo”。“snippet”和“offsets”功能的目的是允许用户识别返回文档中查询术语的位置。“matchinfo”功能为用户提供了可能对根据相关性过滤或排序查询结果有用的指标。
所有三个特殊 SQL 标量函数的第一个参数必须是应用该函数的 FTS 表的FTS 隐藏列。FTS 隐藏列是在所有 FTS 表中找到的自动生成的列,其名称与 FTS 表本身相同。例如,给定一个名为“mail”的 FTS 表:
SELECT offsets(mail) FROM mail WHERE mail MATCH <full-text query expression>; SELECT snippet(mail) FROM mail WHERE mail MATCH <full-text query expression>; SELECT matchinfo(mail) FROM mail WHERE mail MATCH <full-text query expression>;
这三个辅助函数仅在使用 FTS 表的全文索引的 SELECT 语句中有用。如果在使用“按 rowid 查询”或“线性扫描”策略的 SELECT 中使用,则片段和偏移量都返回空字符串,并且 matchinfo 函数返回大小为零字节的 blob 值。
所有三个辅助函数都从 FTS 查询表达式中提取一组“可匹配的短语”以供使用。给定查询的可匹配短语集由表达式中的所有短语(包括未加引号的标记和标记前缀)组成,但前缀为一元“-”运算符(标准语法)或属于子表达式的部分除外用作 NOT 运算符的右侧操作数。
使用以下附带条件,FTS 表中与查询表达式中的一个可匹配短语匹配的每个标记系列被称为“短语匹配”:
- 如果可匹配短语是 FTS 查询表达式中由 NEAR 运算符连接的一系列短语的一部分,则每个短语匹配必须与相关类型的其他短语匹配足够接近以满足 NEAR 条件。
- 如果 FTS 查询中的可匹配短语仅限于匹配指定 FTS 表列中的数据,则仅考虑出现在该列中的短语匹配。
4.1. 偏移函数
对于使用全文索引的 SELECT 查询,offsets() 函数返回包含一系列以空格分隔的整数的文本值。对于当前行的每个短语匹配中的每个术语,返回列表中有四个整数。每组四个整数解释如下:
| Integer | Interpretation |
|---|---|
| 0 | The column number that the term instance occurs in (0 for the leftmost column of the FTS table, 1 for the next leftmost, etc.). |
| 1 | The term number of the matching term within the full-text query expression. Terms within a query expression are numbered starting from 0 in the order that they occur. |
| 2 | The byte offset of the matching term within the column. |
| 3 | The size of the matching term in bytes. |
以下块包含使用偏移函数的示例。
CREATE VIRTUAL TABLE mail USING fts3(subject, body);
INSERT INTO mail VALUES('hello world', 'This message is a hello world message.');
INSERT INTO mail VALUES('urgent: serious', 'This mail is seen as a more serious mail');
-- The following query returns a single row (as it matches only the first
-- entry in table "mail". The text returned by the offsets function is
-- "0 0 6 5 1 0 24 5".
--
-- The first set of four integers in the result indicate that column 0
-- contains an instance of term 0 ("world") at byte offset 6. The term instance
-- is 5 bytes in size. The second set of four integers shows that column 1
-- of the matched row contains an instance of term 0 ("world") at byte offset
-- 24. Again, the term instance is 5 bytes in size.
SELECT offsets(mail) FROM mail WHERE mail MATCH 'world';
-- The following query returns also matches only the first row in table "mail".
-- In this case the returned text is "1 0 5 7 1 0 30 7".
SELECT offsets(mail) FROM mail WHERE mail MATCH 'message';
-- The following query matches the second row in table "mail". It returns the
-- text "1 0 28 7 1 1 36 4". Only those occurrences of terms "serious" and "mail"
-- that are part of an instance of the phrase "serious mail" are identified; the
-- other occurrences of "serious" and "mail" are ignored.
SELECT offsets(mail) FROM mail WHERE mail MATCH '"serious mail"';
4.2. 片段功能
snippet 函数用于创建文档文本的格式化片段,以作为全文查询结果报告的一部分显示。片段函数可以在一到六个参数之间传递,如下所示:
| Argument | Default Value | Description |
|---|---|---|
| 0 | N/A | The first argument to the snippet function must always be the FTS hidden column of the FTS table being queried and from which the snippet is to be taken. The FTS hidden column is an automatically generated column with the same name as the FTS table itself. |
| 1 | "<b>" | The "start match" text. |
| 2 | "</b>" | The "end match" text. |
| 3 | "<b>...</b>" | The "ellipses" text. |
| 4 | -1 | The FTS table column number to extract the returned fragments of text from. Columns are numbered from left to right starting with zero. A negative value indicates that the text may be extracted from any column. |
| 5 | -15 | The absolute value of this integer argument is used as the (approximate) number of tokens to include in the returned text value. The maximum allowable absolute value is 64. The value of this argument is referred to as N in the discussion below. |
snippet 函数首先尝试查找由|N|组成的文本片段 当前行中包含至少一个短语匹配项的当前行中的标记,每个可匹配短语在当前行某处匹配,其中|N| 是传递给代码段函数的第六个参数的绝对值。如果存储在单个列中的文本包含少于 |N| 标记,则考虑整个列值。文本片段不能跨越多列。
如果可以找到这样的文本片段,则返回并进行以下修改:
- 如果文本片段不是从列值的开头开始,则“省略号”文本会添加到它的前面。
- 如果文本片段未在列值的末尾结束,则“省略号”文本将附加到它。
- 对于作为短语匹配一部分的文本片段中的每个标记,“开始匹配”文本插入到标记之前的片段中,“结束匹配”文本紧接着插入。
如果可以找到不止一个这样的片段,那么包含大量“额外”短语匹配的片段将受到青睐。所选文本片段的开头可能会向前或向后移动几个标记,以尝试将短语匹配集中到片段的中心。
假设N是一个正值,如果找不到包含与每个可匹配短语对应的短语匹配的片段,则 snippet 函数会尝试找到两个片段,每个片段大约包含N /2 个标记,它们之间至少包含一个短语匹配每个可匹配短语与当前行匹配的短语。如果失败,则尝试找到三个N /3 令牌片段,最后找到四个N /4 令牌片段。如果找不到包含所需短语匹配的一组四个片段,则选择提供最佳覆盖范围的N /4 个标记的四个片段。
如果N是一个负值,并且找不到包含所需短语匹配的单个片段,则 snippet 函数搜索|N|的两个片段。每个代币,然后三个,然后四个。换句话说,如果指定的N值为负,如果需要一个以上的片段来提供所需的短语匹配覆盖,则片段的大小不会减小。
在找到M个片段后,其中M介于 2 和 4 之间,如上段所述,它们按排序顺序连接在一起,并用“省略号”文本分隔它们。前面列举的三个修改是在文本返回之前对其执行的。
Note: In this block of examples, newlines and whitespace characters have
been inserted into the document inserted into the FTS table, and the expected
results described in SQL comments. This is done to enhance readability only,
they would not be present in actual SQLite commands or output.
-- Create and populate an FTS table.
CREATE VIRTUAL TABLE text USING fts4();
INSERT INTO text VALUES('
During 30 Nov-1 Dec, 2-3oC drops. Cool in the upper portion, minimum temperature 14-16oC
and cool elsewhere, minimum temperature 17-20oC. Cold to very cold on mountaintops,
minimum temperature 6-12oC. Northeasterly winds 15-30 km/hr. After that, temperature
increases. Northeasterly winds 15-30 km/hr.
');
-- The following query returns the text value:
--
-- "<b>...</b>cool elsewhere, minimum temperature 17-20oC. <b>Cold</b> to very
-- <b>cold</b> on mountaintops, minimum temperature 6<b>...</b>".
--
SELECT snippet(text) FROM text WHERE text MATCH 'cold';
-- The following query returns the text value:
--
-- "...the upper portion, [minimum] [temperature] 14-16oC and cool elsewhere,
-- [minimum] [temperature] 17-20oC. Cold..."
--
SELECT snippet(text, '[', ']', '...') FROM text WHERE text MATCH '"min* tem*"'
4.3. 匹配信息函数
matchinfo 函数返回一个 blob 值。如果在不使用全文索引的查询(“按 rowid 查询”或“线性扫描”)中使用它,则 blob 的大小为零字节。否则,blob 由零个或多个机器字节顺序的 32 位无符号整数组成。返回数组中整数的确切数量取决于查询和传递给 matchinfo 函数的第二个参数(如果有)的值。
使用一个或两个参数调用 matchinfo 函数。对于所有辅助函数,第一个参数必须是特殊的 FTS 隐藏列。如果指定了第二个参数,则它必须是仅由字符 'p'、'c'、'n'、'a'、'l'、's'、'x'、'y' 组成的文本值和'b'。如果没有明确提供第二个参数,则默认为“pcx”。第二个参数在下面称为“格式字符串”。
matchinfo 格式字符串中的字符从左到右处理。格式字符串中的每个字符都会导致将一个或多个 32 位无符号整数值添加到返回的数组中。下表中的“值”列包含为每个受支持的格式字符串字符附加到输出缓冲区的整数值的数量。在给出的公式中,cols是 FTS 表中的列 数, phrases是查询中可匹配的短语数。
| Character | Values | Description |
|---|---|---|
| p | 1 | The number of matchable phrases in the query. |
| c | 1 | The number of user defined columns in the FTS table (i.e. not including the docid or the FTS hidden column). |
| x | 3 * cols * phrases |
For each distinct combination of a phrase and table column, the
following three values:
hits_this_row = array[3 * (c + p*cols) + 0]
hits_all_rows = array[3 * (c + p*cols) + 1]
docs_with_hits = array[3 * (c + p*cols) + 2]
|
| y | cols * phrases |
For each distinct combination of a phrase and table column, the
number of usable phrase matches that appear in the column. This is
usually identical to the first value in each set of three returned by the
matchinfo 'x' flag. However, the number of hits reported by the
'y' flag is zero for any phrase that is part of a sub-expression
that does not match the current row. This makes a difference for
expressions that contain AND operators that are descendants of OR
operators. For example, consider the expression:
a OR (b AND c)and the document: "a c d"The matchinfo 'x' flag would report a single hit for the phrases "a" and "c". However, the 'y' directive reports the number of hits for "c" as zero, as it is part of a sub-expression that does not match the document - (b AND c). For queries that do not contain AND operators descended from OR operators, the result values returned by 'y' are always the same as those returned by 'x'. The first value in the array of integer values corresponds to the leftmost column of the table (column 0) and the first phrase in the query (phrase 0). The values corresponding to other column/phrase combinations may be located using the following formula: hits_for_phrase_p_column_c = array[c + p*cols]For queries that use OR expressions, or those that use LIMIT or return many rows, the 'y' matchinfo option may be faster than 'x'. |
| b | ((cols+31)/32) * phrases |
The matchinfo 'b' flag provides similar information to the
matchinfo 'y' flag, but in a more
compact form. Instead of the precise number of hits, 'b' provides a single
boolean flag for each phrase/column combination. If the phrase is present in
the column at least once (i.e. if the corresponding integer output of 'y' would
be non-zero), the corresponding flag is set. Otherwise cleared.
If the table has 32 or fewer columns, a single unsigned integer is output for each phrase in the query. The least significant bit of the integer is set if the phrase appears at least once in column 0. The second least significant bit is set if the phrase appears once or more in column 1. And so on. If the table has more than 32 columns, an extra integer is added to the output of each phrase for each extra 32 columns or part thereof. Integers corresponding to the same phrase are clumped together. For example, if a table with 45 columns is queried for two phrases, 4 integers are output. The first corresponds to phrase 0 and columns 0-31 of the table. The second integer contains data for phrase 0 and columns 32-44, and so on. For example, if nCol is the number of columns in the table, to determine if phrase p is present in column c: p_is_in_c = array[p * ((nCol+31)/32)] & (1 << (c % 32)) |
| n | 1 | The number of rows in the FTS4 table. This value is only available when querying FTS4 tables, not FTS3. |
| a | cols | For each column, the average number of tokens in the text values stored in the column (considering all rows in the FTS4 table). This value is only available when querying FTS4 tables, not FTS3. |
| l | cols | For each column, the length of the value stored in the current row of the FTS4 table, in tokens. This value is only available when querying FTS4 tables, not FTS3. And only if the "matchinfo=fts3" directive was not specified as part of the "CREATE VIRTUAL TABLE" statement used to create the FTS4 table. |
| s | cols | For each column, the length of the longest subsequence of phrase matches that the column value has in common with the query text. For example, if a table column contains the text 'a b c d e' and the query is 'a c "d e"', then the length of the longest common subsequence is 2 (phrase "c" followed by phrase "d e"). |
例如:
-- Create and populate an FTS4 table with two columns:
CREATE VIRTUAL TABLE t1 USING fts4(a, b);
INSERT INTO t1 VALUES('transaction default models default', 'Non transaction reads');
INSERT INTO t1 VALUES('the default transaction', 'these semantics present');
INSERT INTO t1 VALUES('single request', 'default data');
-- In the following query, no format string is specified and so it defaults
-- to "pcx". It therefore returns a single row consisting of a single blob
-- value 80 bytes in size (20 32-bit integers - 1 for "p", 1 for "c" and
-- 3*2*3 for "x"). If each block of 4 bytes in the blob is interpreted
-- as an unsigned integer in machine byte-order, the values will be:
--
-- 3 2 1 3 2 0 1 1 1 2 2 0 1 1 0 0 0 1 1 1
--
-- The row returned corresponds to the second entry inserted into table t1.
-- The first two integers in the blob show that the query contained three
-- phrases and the table being queried has two columns. The next block of
-- three integers describes column 0 (in this case column "a") and phrase
-- 0 (in this case "default"). The current row contains 1 hit for "default"
-- in column 0, of a total of 3 hits for "default" that occur in column
-- 0 of any table row. The 3 hits are spread across 2 different rows.
--
-- The next set of three integers (0 1 1) pertain to the hits for "default"
-- in column 1 of the table (0 in this row, 1 in all rows, spread across
-- 1 rows).
--
SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'default transaction "these semantics"';
-- The format string for this query is "ns". The output array will therefore
-- contain 3 integer values - 1 for "n" and 2 for "s". The query returns
-- two rows (the first two rows in the table match). The values returned are:
--
-- 3 1 1
-- 3 2 0
--
-- The first value in the matchinfo array returned for both rows is 3 (the
-- number of rows in the table). The following two values are the lengths
-- of the longest common subsequence of phrase matches in each column.
SELECT matchinfo(t1, 'ns') FROM t1 WHERE t1 MATCH 'default transaction';
matchinfo 函数比 snippet 或 offsets 函数快得多。这是因为需要实现片段和偏移量才能从磁盘中检索正在分析的文档,而 matchinfo 所需的所有数据都可以作为实现全文索引所需的全文索引的相同部分的一部分。查询本身。这意味着在以下两个查询中,第一个可能比第二个快一个数量级:
SELECT docid, matchinfo(tbl) FROM tbl WHERE tbl MATCH <query expression>; SELECT docid, offsets(tbl) FROM tbl WHERE tbl MATCH <query expression>;
matchinfo 函数提供了计算概率“词袋”相关性分数所需的所有信息,例如 Okapi BM25/BM25F,可用于在全文搜索应用程序中对结果进行排序。本文档的附录 A“搜索应用程序提示”包含有效使用 matchinfo() 函数的示例。
5. Fts4aux - 直接访问全文索引
从版本 3.7.6 (2011-04-12) 开始,SQLite 包含一个名为“fts4aux”的新虚拟表模块,可用于直接检查现有 FTS 表的全文索引。尽管它的名字,fts4aux 与 FTS3 表的工作方式与 FTS4 表一样好。Fts4aux 表是只读的。修改 fts4aux 表内容的唯一方法是修改关联的 FTS 表的内容。fts4aux 模块自动包含在所有包含 FTS 的构建中。
fts4aux 虚拟表是用一个或两个参数构造的。当与单个参数一起使用时,该参数是将用于访问的 FTS 表的非限定名称。要访问不同数据库中的表(例如,创建一个将访问 MAIN 数据库中的 FTS3 表的 TEMP fts4aux 表),请使用双参数形式并给出目标数据库的名称(例如:“main”)在第一个参数中,FTS3/4 表的名称作为第二个参数。(fts4aux 的双参数形式是为 SQLite版本 3.7.17 (2013-05-20) 添加的,并且会在之前的版本中抛出错误。)例如:
-- Create an FTS4 table CREATE VIRTUAL TABLE ft USING fts4(x, y); -- Create an fts4aux table to access the full-text index for table "ft" CREATE VIRTUAL TABLE ft_terms USING fts4aux(ft); -- Create a TEMP fts4aux table accessing the "ft" table in "main" CREATE VIRTUAL TABLE temp.ft_terms_2 USING fts4aux(main,ft);
对于 FTS 表中存在的每个术语,fts4aux 表中有 2 到 N+1 行,其中 N 是关联 FTS 表中用户定义的列数。fts4aux 表始终具有相同的四列,如下所示,从左到右:
| Column Name | Column Contents |
|---|---|
| term | Contains the text of the term for this row. |
| col | This column may contain either the text value '*' (i.e. a single character, U+002a) or an integer between 0 and N-1, where N is again the number of user-defined columns in the corresponding FTS table. |
| documents |
This column always contains an integer value greater than zero.
If the "col" column contains the value '*', then this column contains the number of rows of the FTS table that contain at least one instance of the term (in any column). If col contains an integer value, then this column contains the number of rows of the FTS table that contain at least one instance of the term in the column identified by the col value. As usual, the columns of the FTS table are numbered from left to right, starting with zero. |
| occurrences |
This column also always contains an integer value greater than zero.
If the "col" column contains the value '*', then this column contains the total number of instances of the term in all rows of the FTS table (in any column). Otherwise, if col contains an integer value, then this column contains the total number of instances of the term that appear in the FTS table column identified by the col value. |
| languageid (hidden) |
This column determines which languageid is used to
extract vocabulary from the FTS3/4 table.
The default value for languageid is 0. If an alternative language is specified in WHERE clause constraints, then that alternative is used instead of 0. There can only be a single languageid per query. In other words, the WHERE clause cannot contain a range constraint or IN operator on the languageid. |
例如,使用上面创建的表:
INSERT INTO ft(x, y) VALUES('Apple banana', 'Cherry');
INSERT INTO ft(x, y) VALUES('Banana Date Date', 'cherry');
INSERT INTO ft(x, y) VALUES('Cherry Elderberry', 'Elderberry');
-- The following query returns this data:
--
-- apple | * | 1 | 1
-- apple | 0 | 1 | 1
-- banana | * | 2 | 2
-- banana | 0 | 2 | 2
-- cherry | * | 3 | 3
-- cherry | 0 | 1 | 1
-- cherry | 1 | 2 | 2
-- date | * | 1 | 2
-- date | 0 | 1 | 2
-- elderberry | * | 1 | 2
-- elderberry | 0 | 1 | 1
-- elderberry | 1 | 1 | 1
--
SELECT term, col, documents, occurrences FROM ft_terms;
在示例中,“term”列中的值都是小写的,即使它们以混合大小写的形式插入到表“ft”中。这是因为 fts4aux 表包含分词器从文档文本中提取的术语。在这种情况下,由于表“ft”使用 简单的分词器,这意味着所有术语都已折叠为小写。此外,(例如)没有行的列“term”设置为“apple”且列“col”设置为 1。由于第 1 列中没有术语“apple”的实例,因此没有行存在于fts4aux 表。
在事务期间,一些写入 FTS 表的数据可能会缓存在内存中,只有在提交事务时才写入数据库。然而,fts4aux 模块的实现只能从数据库中读取数据。实际上,这意味着如果从已修改关联的 FTS 表的事务中查询 fts4aux 表,则查询结果可能仅反映所做更改的一个(可能为空)子集。
6.FTS4选项
如果“CREATE VIRTUAL TABLE”语句指定模块 FTS4(而非 FTS3),则特殊指令 - FTS4 选项 - 类似于“tokenize=*”选项也可能出现在列名称的位置。FTS4 选项由选项名称、后跟“=”字符和选项值组成。选项值可以选择用单引号或双引号括起来,嵌入的引号字符以与 SQL 文字相同的方式转义。“=”字符两边不能有空格。例如,要创建一个 FTS4 表,并将选项“matchinfo”的值设置为“fts3”:
-- Create a reduced-footprint FTS4 table. CREATE VIRTUAL TABLE papers USING fts4(author, document, matchinfo=fts3);
FTS4 目前支持以下选项:
| Option | Interpretation |
|---|---|
| compress | The compress option is used to specify the compress function. It is an error to specify a compress function without also specifying an uncompress function. See below for details. |
| content | The content allows the text being indexed to be stored in a separate table distinct from the FTS4 table, or even outside of SQLite. |
| languageid | The languageid option causes the FTS4 table to have an additional hidden integer column that identifies the language of the text contained in each row. The use of the languageid option allows the same FTS4 table to hold text in multiple languages or scripts, each with different tokenizer rules, and to query each language independently of the others. |
| matchinfo | When set to the value "fts3", the matchinfo option reduces the amount of information stored by FTS4 with the consequence that the "l" option of matchinfo() is no longer available. |
| notindexed | This option is used to specify the name of a column for which data is not indexed. Values stored in columns that are not indexed are not matched by MATCH queries. Nor are they recognized by auxiliary functions. A single CREATE VIRTUAL TABLE statement may have any number of notindexed options. |
| order | The "order" option may be set to either "DESC" or "ASC" (in upper or lower case). If it is set to "DESC", then FTS4 stores its data in such a way as to optimize returning results in descending order by docid. If it is set to "ASC" (the default), then the data structures are optimized for returning results in ascending order by docid. In other words, if many of the queries run against the FTS4 table use "ORDER BY docid DESC", then it may improve performance to add the "order=desc" option to the CREATE VIRTUAL TABLE statement. |
| prefix | This option may be set to a comma-separated list of positive non-zero integers. For each integer N in the list, a separate index is created in the database file to optimize prefix queries where the query term is N bytes in length, not including the '*' character, when encoded using UTF-8. See below for details. |
| uncompress | This option is used to specify the uncompress function. It is an error to specify an uncompress function without also specifying a compress function. See below for details. |
使用 FTS4 时,指定包含“=”字符且既不是“tokenize=*”规范也不是公认的 FTS4 选项的列名是错误的。使用 FTS3,无法识别的指令中的第一个标记被解释为列名。同样,在使用 FTS4 时,在单个表声明中指定多个“tokenize=*”指令是错误的,而 FTS3 将第二个和后续“tokenize=*”指令解释为列名。例如:
-- An error. FTS4 does not recognize the directive "xyz=abc". CREATE VIRTUAL TABLE papers USING fts4(author, document, xyz=abc); -- Create an FTS3 table with three columns - "author", "document" -- and "xyz". CREATE VIRTUAL TABLE papers USING fts3(author, document, xyz=abc); -- An error. FTS4 does not allow multiple tokenize=* directives CREATE VIRTUAL TABLE papers USING fts4(tokenize=porter, tokenize=simple); -- Create an FTS3 table with a single column named "tokenize". The -- table uses the "porter" tokenizer. CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple); -- An error. Cannot create a table with two columns named "tokenize". CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple, tokenize=icu);
6.1. compress= 和 uncompress= 选项
压缩和解压缩选项允许 FTS4 内容以压缩形式存储在数据库中。这两个选项都应设置为使用 接受单个参数的 sqlite3_create_function()注册的 SQL 标量函数的名称。
压缩函数应该返回作为参数传递给它的值的压缩版本。每次将数据写入 FTS4 表时,每个列值都会传递给压缩函数,并将结果值存储在数据库中。compress 函数可以返回任何类型的 SQLite 值(blob、文本、实数、整数或 null)。
uncompress 函数应解压缩先前由 compress 函数压缩的数据。换句话说,对于所有 SQLite 值 X,uncompress(compress(X)) 等于 X 应该是真的。当 FTS4 从数据库中读取由 compress 函数压缩的数据时,它被传递给 uncompress 函数在使用之前。
如果指定的压缩或解压缩函数不存在,则可能仍会创建表。直到读取FTS4表(如果uncompress函数不存在)或写入(如果是compress函数不存在)才会返回错误。
-- Create an FTS4 table that stores data in compressed form. This -- assumes that the scalar functions zip() and unzip() have been (or -- will be) added to the database handle. CREATE VIRTUAL TABLE papers USING fts4(author, document, compress=zip, uncompress=unzip);
在实现压缩和解压缩功能时,注意数据类型很重要。具体来说,当用户从压缩的FTS表中读取一个值时,FTS返回的值与解压缩函数返回的值完全相同,包括数据类型。如果该数据类型与传递给压缩函数的原始值的数据类型不同(例如,如果压缩最初传递给 TEXT 时解压缩函数返回 BLOB),则用户查询可能无法按预期运行。
6.2. 内容=选项
内容选项允许 FTS4 放弃存储被索引的文本。content 选项可以通过两种方式使用:
索引文档根本不存储在 SQLite 数据库中(“无内容”FTS4 表),或者
索引文档存储在由用户创建和管理的数据库表中(“外部内容”FTS4 表)。
因为索引文档本身通常比全文索引大得多,所以可以使用内容选项来实现显着的空间节省。
6.2.1. 无内容的 FTS4 表
为了创建一个根本不存储索引文档副本的 FTS4 表,内容选项应设置为空字符串。例如,以下 SQL 创建这样一个包含三列的 FTS4 表 - “a”、“b”和“c”:
CREATE VIRTUAL TABLE t1 USING fts4(content="", a, b, c);
可以使用 INSERT 语句将数据插入到这样的 FTS4 表中。然而,与普通的 FTS4 表不同,用户必须提供一个明确的整数 docid 值。例如:
-- This statement is Ok:
INSERT INTO t1(docid, a, b, c) VALUES(1, 'a b c', 'd e f', 'g h i');
-- This statement causes an error, as no docid value has been provided:
INSERT INTO t1(a, b, c) VALUES('j k l', 'm n o', 'p q r');
无法更新或删除存储在无内容 FTS4 表中的行。尝试这样做是错误的。
无内容的 FTS4 表也支持 SELECT 语句。但是,尝试检索 docid 列以外的任何表列的值都是错误的。可以使用辅助函数 matchinfo(),但不能使用 snippet() 和 offsets()。例如:
-- The following statements are Ok: SELECT docid FROM t1 WHERE t1 MATCH 'xxx'; SELECT docid FROM t1 WHERE a MATCH 'xxx'; SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'xxx'; -- The following statements all cause errors, as the value of columns -- other than docid are required to evaluate them. SELECT * FROM t1; SELECT a, b FROM t1 WHERE t1 MATCH 'xxx'; SELECT docid FROM t1 WHERE a LIKE 'xxx%'; SELECT snippet(t1) FROM t1 WHERE t1 MATCH 'xxx';
与尝试检索 docid 以外的列值相关的错误是在 sqlite3_step() 中发生的运行时错误。在某些情况下,例如,如果 SELECT 查询中的 MATCH 表达式匹配零行,则即使语句确实引用 docid 以外的列值,也可能根本没有错误。
6.2.2. 外部内容 FTS4 表
“外部内容”FTS4 表类似于无内容表,除了如果查询的评估需要 docid 以外的列的值,FTS4 会尝试从指定的表(或视图或虚拟表)中检索该值用户(以下简称“内容表”)。FTS4模块从不写入内容表,写入内容表不影响全文索引。用户有责任确保内容表和全文索引一致。
通过将内容选项设置为表(或视图或虚拟表)的名称来创建外部内容 FTS4 表,FTS4 可以查询该表以在需要时检索列值。如果指定的表不存在,则外部内容表的行为方式与无内容表相同。例如:
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c); CREATE VIRTUAL TABLE t3 USING fts4(content="t2", a, c);
假设指定的表确实存在,那么它的列必须与为 FTS 表定义的列相同或者是它们的超集。外部表也必须与 FTS 表位于同一个数据库文件中。换句话说,外部表不能位于使用 ATTACH连接的不同数据库文件中,当另一个位于持久数据库文件(如 MAIN)中时,FTS 表和外部内容之一也不能位于 TEMP 数据库中。
当用户对 FTS 表的查询需要除 docid 之外的列值时,FTS 会尝试从内容表中行的相应列中读取请求的值,其 rowid 值等于当前 FTS docid。只能查询在 FTS/34 表声明中重复的内容表列的子集——要从必须直接查询内容表的任何其他列中检索值。或者,如果在内容表中找不到这样的行,则使用 NULL 值代替。例如:
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c); CREATE VIRTUAL TABLE t3 USING fts4(content="t2", b, c); INSERT INTO t2 VALUES(2, 'a b', 'c d', 'e f'); INSERT INTO t2 VALUES(3, 'g h', 'i j', 'k l'); INSERT INTO t3(docid, b, c) SELECT id, b, c FROM t2; -- The following query returns a single row with two columns containing -- the text values "i j" and "k l". -- -- The query uses the full-text index to discover that the MATCH -- term matches the row with docid=3. It then retrieves the values -- of columns b and c from the row with rowid=3 in the content table -- to return. -- SELECT * FROM t3 WHERE t3 MATCH 'k'; -- Following the UPDATE, the query still returns a single row, this -- time containing the text values "xxx" and "yyy". This is because the -- full-text index still indicates that the row with docid=3 matches -- the FTS4 query 'k', even though the documents stored in the content -- table have been modified. -- UPDATE t2 SET b = 'xxx', c = 'yyy' WHERE rowid = 3; SELECT * FROM t3 WHERE t3 MATCH 'k'; -- Following the DELETE below, the query returns one row containing two -- NULL values. NULL values are returned because FTS is unable to find -- a row with rowid=3 within the content table. -- DELETE FROM t2; SELECT * FROM t3 WHERE t3 MATCH 'k';
当从外部内容 FTS4 表中删除一行时,FTS4 需要从内容表中检索被删除行的列值。这是为了让 FTS4 可以更新已删除行中出现的每个标记的全文索引条目,以指示该行已被删除。如果找不到内容表行,或者它包含与 FTS 索引内容不一致的值,则结果可能难以预测。FTS 索引可能会保留包含与已删除行对应的条目,这可能导致后续 SELECT 查询返回看似无意义的结果。这同样适用于更新行时,因为在内部 UPDATE 与 DELETE 后跟 INSERT 相同。
这意味着为了使 FTS 与外部内容表保持同步,任何 UPDATE 或 DELETE 操作都必须首先应用于 FTS 表,然后再应用于外部内容表。例如:
CREATE TABLE t1_real(id INTEGER PRIMARY KEY, a, b, c, d); CREATE VIRTUAL TABLE t1_fts USING fts4(content="t1_real", b, c); -- This works. When the row is removed from the FTS table, FTS retrieves -- the row with rowid=123 and tokenizes it in order to determine the entries -- that must be removed from the full-text index. -- DELETE FROM t1_fts WHERE rowid = 123; DELETE FROM t1_real WHERE rowid = 123; -- This does not work. By the time the FTS table is updated, the row -- has already been deleted from the underlying content table. As a result -- FTS is unable to determine the entries to remove from the FTS index and -- so the index and content table are left out of sync. -- DELETE FROM t1_real WHERE rowid = 123; DELETE FROM t1_fts WHERE rowid = 123;
一些用户可能希望使用数据库触发器来使全文索引相对于内容表中存储的文档集保持最新,而不是分别写入全文索引和内容表。例如,使用前面示例中的表:
CREATE TRIGGER t2_bu BEFORE UPDATE ON t2 BEGIN DELETE FROM t3 WHERE docid=old.rowid; END; CREATE TRIGGER t2_bd BEFORE DELETE ON t2 BEGIN DELETE FROM t3 WHERE docid=old.rowid; END; CREATE TRIGGER t2_au AFTER UPDATE ON t2 BEGIN INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c); END; CREATE TRIGGER t2_ai AFTER INSERT ON t2 BEGIN INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c); END;
必须在对内容表进行实际删除之前触发 DELETE 触发器。这样 FTS4 仍然可以检索原始值以更新全文索引。并且插入新行后必须触发INSERT触发器,以处理系统自动分配rowid的情况。出于同样的原因,UPDATE 触发器必须分为两部分,一部分在更新内容表之前触发,另一部分在更新内容表之后触发。
FTS4“重建”命令 删除 整个全文索引,并根据内容表中的当前文档集重建它。再次假设“t3”是外部内容 FTS4 表的名称,重建命令如下所示:
INSERT INTO t3(t3) VALUES('rebuild');
此命令也可用于普通的 FTS4 表,例如,如果分词器的实现发生变化。尝试重建由无内容 FTS4 表维护的全文索引是错误的,因为没有内容可用于重建。
6.3. languageid= 选项
当 languageid 选项存在时,它指定添加到 FTS4 表的另一个隐藏列的名称,用于指定存储在 FTS4 表的每一行中的语言。languageid 隐藏列的名称必须与 FTS4 表中的所有其他列名称不同。例子:
CREATE VIRTUAL TABLE t1 USING fts4(x, y, languageid="lid")
languageid 列的默认值为 0。插入 languageid 列的任何值都将转换为 32 位(而非 64 位)有符号整数。
默认情况下,FTS 查询(使用 MATCH 运算符的查询)仅考虑 languageid 列设置为 0 的那些行。要查询具有其他 languageid 值的行,形式为“
SELECT * FROM t1 WHERE t1 MATCH 'abc' AND lid=5;
单个 FTS 查询不可能返回具有不同 languageid 值的行。添加使用其他运算符(例如 lid!=5 或 lid<=5)的 WHERE 子句的结果是未定义的。
如果 content 选项与 languageid 选项一起使用,则命名的 languageid 列必须存在于 content= 表中(遵守通常的规则 - 如果查询从不需要读取内容表,则此限制不适用)。
当使用 languageid 选项时,SQLite 在创建对象后立即调用 sqlite3_tokenizer_module 对象上的 xLanguageid() 以传递标记器应使用的语言 id。xLanguageid() 方法绝不会为任何单个分词器对象调用多次。不同语言可能被不同地标记化这一事实是没有单个 FTS 查询可以返回具有不同 languageid 值的行的原因之一。
6.4. matchinfo= 选项
matchinfo 选项只能设置为值“fts3”。尝试将 matchinfo 设置为“fts3”以外的任何内容都是错误的。如果指定了此选项,则会省略 FTS4 存储的一些额外信息。这减少了 FTS4 表消耗的磁盘空间量,直到它几乎与等效的 FTS3 表使用的空间量相同,但也意味着通过将 'l' 标志传递给matchinfo()功能不可用。
6.5. notindexed= 选项
通常,FTS 模块维护表中所有列中所有项的倒排索引。此选项用于指定不应将条目添加到索引的列的名称。多个“notindexed”选项可用于指定应从索引中省略多个列。例如:
-- Create an FTS4 table for which only the contents of columns c2 and c4 -- are tokenized and added to the inverted index. CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, c3, c4, notindexed=c1, notindexed=c3);
存储在未索引列中的值不符合匹配 MATCH 运算符的条件。它们不影响 offsets() 或 matchinfo() 辅助函数的结果。snippet() 函数也不会根据存储在未索引列中的值返回片段。
6.6. 前缀=选项
FTS4 前缀选项使 FTS 以与始终索引完整术语相同的方式索引指定长度的术语前缀。前缀选项必须设置为逗号分隔的非零正整数列表。对于列表中的每个值 N,长度为 N 字节的前缀(当使用 UTF-8 编码时)被索引。FTS4 使用术语前缀索引来加速 前缀查询。当然,代价是索引术语前缀和完整术语会增加数据库大小并减慢 FTS4 表上的写入操作。
在两种情况下, 前缀索引可用于优化前缀查询。如果查询是针对 N 字节的前缀,则使用“prefix=N”创建的前缀索引可提供最佳优化。或者,如果没有可用的“prefix=N”索引,则可以使用“prefix=N+1”索引。使用“prefix=N+1”索引的效率低于“prefix=N”索引,但总比没有前缀索引要好。
-- Create an FTS4 table with indexes to optimize 2 and 4 byte prefix queries. CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, prefix="2,4"); -- The following two queries are both optimized using the prefix indexes. SELECT * FROM t1 WHERE t1 MATCH 'ab*'; SELECT * FROM t1 WHERE t1 MATCH 'abcd*'; -- The following two queries are both partially optimized using the prefix -- indexes. The optimization is not as pronounced as it is for the queries -- above, but still an improvement over no prefix indexes at all. SELECT * FROM t1 WHERE t1 MATCH 'a*'; SELECT * FROM t1 WHERE t1 MATCH 'abc*';
7. FTS3 和 FTS4 的特殊命令
特殊的 INSERT 操作可用于向 FTS3 和 FTS4 表发出命令。每个 FTS3 和 FTS4 都有一个隐藏的只读列,它与表本身同名。插入到这个隐藏列中的 INSERT 被解释为对 FTS3/4 表的命令。对于名为“xyz”的表,支持以下命令:
插入 xyz(xyz) 值('优化');
插入 xyz(xyz) 值('重建');
插入 xyz(xyz) VALUES('完整性检查');
插入 xyz(xyz) VALUES('merge=X,Y');
插入 xyz(xyz) VALUES('automerge=N');
7.1. “优化”命令
“优化”命令导致 FTS3/4 将其所有倒排索引 b 树合并为一个大而完整的 b 树。进行优化将使后续查询运行得更快,因为要搜索的 b 树更少,并且它可以通过合并冗余条目来减少磁盘使用。但是,对于大型 FTS 表,运行优化可能与运行VACUUM一样昂贵。优化命令本质上必须读取和写入整个 FTS 表,从而导致大事务。
在批处理模式操作中,FTS 表最初是使用大量 INSERT 操作构建的,然后在没有进一步更改的情况下重复查询,在最后一次 INSERT 之后和第一次查询之前运行“优化”通常是个好主意。
7.2. “重建”命令
“重建”命令导致 SQLite 丢弃整个 FTS3/4 表,然后从原始文本重新重建它。这个概念类似于REINDEX,只是它适用于 FTS3/4 表而不是普通索引。
只要自定义分词器的实现发生变化,就应该运行“重建”命令,以便所有内容都可以重新分词。在对原始内容表进行更改后 使用FTS4 内容选项时,“重建”命令也很有用 。
7.3. “完整性检查”命令
“完整性检查”命令使 SQLite 通过将这些倒排索引与原始内容进行比较来读取和验证 FTS3/4 表中所有倒排索引的准确性。如果倒排索引一切正常,“完整性检查”命令会自动成功,但如果发现任何问题,则会失败并出现 SQLITE_CORRUPT 错误。
“完整性检查”命令在概念上类似于 PRAGMA integrity_check。在工作系统中,“完整性命令”应该总是成功的。完整性检查失败的可能原因包括:
- 应用程序直接更改了FTS 影子表 ,而没有使用 FTS3/4 虚拟表,导致影子表彼此不同步。
- 使用FTS4 内容选项并且未能手动使内容与 FTS4 倒排索引保持同步。
- FTS3/4 虚拟表中的错误。(“完整性检查”命令最初被设想为 FTS3/4 测试套件的一部分。)
- 底层 SQLite 数据库文件损坏。(有关其他信息,请参阅有关如何破坏和 SQLite 数据库的文档。)
7.4. “merge=X,Y”命令
“merge=X,Y”命令(其中 X 和 Y 是整数)使 SQLite 做有限的工作,将 FTS3/4 表的各种倒排索引 b 树合并成一个大的 b 树。X 值是要合并的“块”的目标数量,Y 是在将合并应用到该级别之前所需级别上的 b 树段的最小数量。Y的值应在2到16之间,推荐值为8。X的值可以是任何正整数,但推荐值在100到300之间。
当 FTS 表在同一级别累积 16 个 b-tree 段时,对该表的下一个 INSERT 将导致所有 16 个段合并到下一个更高级别的单个 b-tree 段。这些级别合并的效果是大多数 INSERT 到 FTS 表的速度非常快并且占用的内存最少,但偶尔的 INSERT 速度很慢并且由于需要进行合并而生成大事务。这会导致 INSERT 的“尖峰”性能。
为避免 INSERT 性能突然下降,应用程序可以定期运行“merge=X,Y”命令,可能在空闲线程或空闲进程中,以确保 FTS 表永远不会在同一级别累积过多的 b 树段。通过在每几千个文档插入后运行“merge=X,Y”,通常可以避免 INSERT 性能峰值,并且可以最大化 FTS3/4 的性能。每个“merge=X,Y”命令将在单独的事务中运行(当然,除非它们使用BEGIN ... COMMIT组合在一起)。通过在 100 到 300 的范围内选择 X 的值,可以使事务保持较小。在每个“merge=X,Y”命令之前和之后,当差异低于 2 时停止循环。
7.5. “automerge=N”命令
“automerge=N”命令(其中 N 是 0 到 15 之间的整数,包括在内)用于配置 FTS3/4 表的“automerge”参数,该参数控制自动增量倒排索引合并。新表的默认 automerge 值为 0,表示完全禁用自动增量合并。如果使用“automerge=N”命令修改了 automerge 参数的值,则新参数值将永久存储在数据库中,并由所有随后建立的数据库连接使用。
将 automerge 参数设置为非零值可启用自动增量合并。这会导致 SQLite 在每次 INSERT 操作后进行少量倒排索引合并。执行合并的数量经过设计,因此 FTS3/4 表永远不会达到它在同一级别有 16 个段的点,因此必须进行大量合并才能完成插入。换句话说,自动增量合并旨在防止 INSERT 性能突然下降。
自动增量合并的缺点是它使 FTS3/4 表上的每个 INSERT、UPDATE 和 DELETE 操作运行得稍微慢一些,因为必须使用额外的时间来执行增量合并。为了获得最佳性能,建议应用程序禁用自动增量合并,而是在空闲进程中使用 “合并”命令来保持倒排索引的良好合并。但是如果应用程序的结构不容易允许空闲进程,那么使用自动增量合并是一个非常合理的回退解决方案。
automerge 参数的实际值决定了自动倒排索引合并同时合并的索引段的数量。如果该值设置为 N,则系统会等到单个级别上至少有 N 个段,然后才开始增量合并它们。设置较低的 N 值会导致更快地合并段,这可能会加速全文查询,并且如果工作负载包含 UPDATE 或 DELETE 操作以及 INSERT,则会减少全文索引占用的磁盘空间。但是,它也会增加写入磁盘的数据量。
对于工作负载包含少量 UPDATE 或 DELETE 操作的情况下的一般用途,automerge 的一个不错选择是 8。如果工作负载包含许多 UPDATE 或 DELETE 命令,或者查询速度是一个问题,则将 automerge 减少到 2 可能是有利的.
出于向后兼容性的原因,“automerge=1”命令将 automerge 参数设置为 8,而不是 1(值 1 无论如何都没有意义,因为合并来自单个段的数据是空操作)。
8.分词器
FTS 分词器是一组用于从文档或基本 FTS 全文查询中提取术语的规则。
除非将特定分词器指定为用于创建 FTS 表的 CREATE VIRTUAL TABLE 语句的一部分,否则将使用默认分词器“simple”。简单分词器根据以下规则从文档或基本 FTS 全文查询中提取分词:
术语是符合条件的字符的连续序列,其中符合条件的字符是所有字母数字字符和 Unicode 代码点值大于或等于 128 的所有字符。将文档拆分为术语时,将丢弃所有其他字符。它们的唯一贡献是分隔相邻的项。
作为标记化过程的一部分,ASCII 范围内的所有大写字符(Unicode 代码点小于 128)都将转换为其等效的小写字符。因此,在使用简单分词器时,全文查询不区分大小写。
例如,当文档包含文本“Right now, they're very frustrument.”时,从文档中提取并添加到全文索引中的术语按顺序为“right now they re very frustrated”。这样的文档将匹配全文查询,例如“MATCH 'Frustrated'”,因为简单分词器在搜索全文索引之前将查询中的术语转换为小写。
除了“简单”的分词器外,FTS 源代码还具有使用波特词干算法的分词器. 此分词器使用相同的规则将输入文档分成术语,包括将所有术语折叠成小写,而且还使用 Porter 词干算法将相关的英语单词简化为一个公共词根。例如,使用与上段中相同的输入文档,porter 标记器提取以下标记:“right now thei veri frustrat”。尽管其中一些术语甚至不是英语单词,但在某些情况下,使用它们构建全文索引比简单分词器生成的更易于理解的输出更有用。使用 porter 分词器,文档不仅可以匹配全文查询,例如“MATCH 'Frustrated'”,还可以匹配诸如“MATCH 'Frustration'”之类的查询,作为术语“Frustration” 被 Porter stemmer 算法简化为“frustrat”——就像“Frustrated”一样。因此,当使用 porter tokenizer 时,FTS 不仅能够找到查询术语的精确匹配,还能找到与相似英语术语的匹配。有关 Porter Stemmer 算法的更多信息,请参阅上面链接的页面。
说明“简单”和“搬运工”分词器之间区别的示例:
-- Create a table using the simple tokenizer. Insert a document into it.
CREATE VIRTUAL TABLE simple USING fts3(tokenize=simple);
INSERT INTO simple VALUES('Right now they''re very frustrated');
-- The first of the following two queries matches the document stored in
-- table "simple". The second does not.
SELECT * FROM simple WHERE simple MATCH 'Frustrated';
SELECT * FROM simple WHERE simple MATCH 'Frustration';
-- Create a table using the porter tokenizer. Insert the same document into it
CREATE VIRTUAL TABLE porter USING fts3(tokenize=porter);
INSERT INTO porter VALUES('Right now they''re very frustrated');
-- Both of the following queries match the document stored in table "porter".
SELECT * FROM porter WHERE porter MATCH 'Frustrated';
SELECT * FROM porter WHERE porter MATCH 'Frustration';
如果此扩展是使用定义的 SQLITE_ENABLE_ICU 预处理器符号编译的,则存在使用 ICU 库实现的名为“icu”的内置分词器。传递给此分词器的 xCreate() 方法(参见 fts3_tokenizer.h)的第一个参数可能是 ICU 区域设置标识符。例如,“tr_TR”代表在土耳其使用的土耳其语,或者“en_AU”代表在澳大利亚使用的英语。例如:
CREATE VIRTUAL TABLE thai_text USING fts3(text, tokenize=icu th_TH)
ICU 分词器实现非常简单。它根据查找单词边界的 ICU 规则拆分输入文本,并丢弃任何完全由空白组成的标记。这可能适用于某些地区的某些应用程序,但不是全部。如果需要更复杂的处理,例如实现词干提取或丢弃标点符号,这可以通过创建一个使用 ICU 分词器作为其实现的一部分的分词器实现来完成。
“unicode61”分词器从 SQLite版本 3.7.13 (2012-06-11) 开始可用。Unicode61 的工作方式与“简单”非常相似,只是它根据 Unicode 版本 6.1 中的规则进行简单的 unicode 大小写折叠,并且它识别 unicode 空格和标点字符并使用它们来分隔标记。simple tokenizer 仅对 ASCII 字符进行大小写折叠,并且仅将 ASCII 空格和标点字符识别为标记分隔符。
默认情况下,“unicode61”尝试从拉丁脚本字符中删除变音符号。可以通过添加分词器参数“remove_diacritics=0”来覆盖此行为。例如:
-- Create tables that remove alldiacritics from Latin script characters -- as part of tokenization. CREATE VIRTUAL TABLE txt1 USING fts4(tokenize=unicode61); CREATE VIRTUAL TABLE txt2 USING fts4(tokenize=unicode61 "remove_diacritics=2"); -- Create a table that does not remove diacritics from Latin script -- characters as part of tokenization. CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "remove_diacritics=0");
remove_diacritics 选项可以设置为“0”、“1”或“2”。默认值为“1”。如果它被设置为“1”或“2”,那么变音符号将如上所述从拉丁脚本字符中移除。但是,如果将其设置为“1”,则在使用单个 unicode 代码点来表示具有多个变音符号的字符的相当罕见的情况下,变音符号不会被删除。例如,变音符号不会从代码点 0x1ED9(“拉丁文小写字母 O 带圆弧和点下方”)中删除。这在技术上是一个错误,但在不产生向后兼容性问题的情况下无法修复。如果此选项设置为“2”,则会正确地从所有拉丁字符中删除变音符号。
也可以自定义 unicode61 将其视为分隔符的代码点集。“separators=”选项可用于指定一个或多个应被视为分隔符的额外字符,“tokenchars=”选项可用于指定一个或多个应被视为令牌一部分的额外字符of 作为分隔符。例如:
-- Create a table that uses the unicode61 tokenizer, but considers "." -- and "=" characters to be part of tokens, and capital "X" characters to -- function as separators. CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "tokenchars=.=" "separators=X"); -- Create a table that considers space characters (codepoint 32) to be -- a token character CREATE VIRTUAL TABLE txt4 USING fts4(tokenize=unicode61 "tokenchars= ");
如果指定为“tokenchars=”参数一部分的字符在默认情况下被认为是标记字符,则会被忽略。即使它已被早期的“separators=”选项标记为分隔符,也是如此。同样,如果指定为“separators=”选项一部分的字符在默认情况下被视为分隔符,则会被忽略。如果指定了多个“tokenchars=”或“separators=”选项,则会处理所有选项。例如:
-- Create a table that uses the unicode61 tokenizer, but considers "."
-- and "=" characters to be part of tokens, and capital "X" characters to
-- function as separators. Both of the "tokenchars=" options are processed
-- The "separators=" option ignores the "." passed to it, as "." is by
-- default a separator character, even though it has been marked as a token
-- character by an earlier "tokenchars=" option.
CREATE VIRTUAL TABLE txt5 USING fts4(
tokenize=unicode61 "tokenchars=." "separators=X." "tokenchars=="
);
传递给“tokenchars=”或“separators=”选项的参数区分大小写。在上面的示例中,将“X”指定为分隔符不会影响“x”的处理方式。
8.1. 自定义(应用程序定义的)分词器
除了提供内置的“simple”、“porter”和(可能)“icu”和“unicode61”标记器之外,FTS 还为应用程序提供了一个接口来实现和注册用 C 编写的自定义标记器。该接口用于创建一个新的tokenizer 在 fts3_tokenizer.h 源文件中定义和描述。
注册一个新的 FTS 分词器类似于用 SQLite 注册一个新的虚拟表模块。用户将指针传递给一个结构,该结构包含指向各种回调函数的指针,这些回调函数构成了新标记器类型的实现。对于分词器,结构(在 fts3_tokenizer.h 中定义)称为“sqlite3_tokenizer_module”。
FTS 不公开用户调用以使用数据库句柄注册新标记器类型的 C 函数。相反,指针必须编码为 SQL blob 值,并通过评估特殊标量函数“fts3_tokenizer()”通过 SQL 引擎传递给 FTS。可以使用一个或两个参数调用 fts3_tokenizer() 函数,如下所示:
SELECT fts3_tokenizer(<tokenizer-name>); SELECT fts3_tokenizer(<tokenizer-name>, <sqlite3_tokenizer_module ptr>);
其中 <tokenizer-name> 是使用 sqlite3_bind_text()将字符串绑定到的参数,其中字符串标识标记器,<sqlite3_tokenizer_module ptr> 是使用sqlite3_bind_blob()将 BLOB 绑定到的参数,其中 BLOB的值是指向 sqlite3_tokenizer_module 结构的指针。如果存在第二个参数,则将其注册为 tokenizer <tokenizer-name> 并返回其副本。如果仅传递一个参数,则返回指向当前注册为 <tokenizer-name> 的分词器实现的指针,编码为 blob。或者,如果不存在这样的分词器,则会引发 SQL 异常(错误)。
在 SQLite版本 3.11.0 (2016-02-15) 之前,fts3_tokenzer() 的参数可以是文字字符串或 BLOB。它们不必是绑定参数。但这可能会在发生 SQL 注入时导致安全问题。因此,遗留行为现在默认被禁用。但是可以启用旧的遗留行为,以便在真正需要它的应用程序中向后兼容,通过调用 sqlite3_db_config (db, SQLITE_DBCONFIG_ENABLE_FTS3_TOKENIZER ,1,0)。
以下块包含从 C 代码调用 fts3_tokenizer() 函数的示例:
/*
** Register a tokenizer implementation with FTS3 or FTS4.
*/
int registerTokenizer(
sqlite3 *db,
char *zName,
const sqlite3_tokenizer_module *p
){
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?1, ?2)";
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
sqlite3_bind_blob(pStmt, 2, &p, sizeof(p), SQLITE_STATIC);
sqlite3_step(pStmt);
return sqlite3_finalize(pStmt);
}
/*
** Query FTS for the tokenizer implementation named zName.
*/
int queryTokenizer(
sqlite3 *db,
char *zName,
const sqlite3_tokenizer_module **pp
){
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?)";
*pp = 0;
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
if( SQLITE_ROW==sqlite3_step(pStmt) ){
if( sqlite3_column_type(pStmt, 0)==SQLITE_BLOB ){
memcpy(pp, sqlite3_column_blob(pStmt, 0), sizeof(*pp));
}
}
return sqlite3_finalize(pStmt);
}
8.2. 查询分词器
“fts3tokenize”虚拟表可用于直接访问任何分词器。以下 SQL 演示了如何创建 fts3tokenize 虚拟表的实例:
CREATE VIRTUAL TABLE tok1 USING fts3tokenize('porter');
当然,应该用所需分词器的名称代替示例中的“porter”。如果分词器需要一个或多个参数,它们应该在 fts3tokenize 声明中以逗号分隔(即使它们在常规 fts4 表的声明中以空格分隔)。以下创建使用相同分词器的 fts4 和 fts3tokenize 表:
CREATE VIRTUAL TABLE text1 USING fts4(tokenize=icu en_AU); CREATE VIRTUAL TABLE tokens1 USING fts3tokenize(icu, en_AU); CREATE VIRTUAL TABLE text2 USING fts4(tokenize=unicode61 "tokenchars=@." "separators=123"); CREATE VIRTUAL TABLE tokens2 USING fts3tokenize(unicode61, "tokenchars=@.", "separators=123");
创建虚拟表后,可以按如下方式查询:
SELECT token, start, end, position FROM tok1 WHERE input='This is a test sentence.';
虚拟表将为输入字符串中的每个标记返回一行输出。“令牌”列是令牌的文本。“开始”和“结束”列是原始输入字符串中标记开始和结束的字节偏移量。“位置”列是令牌在原始输入字符串中的序号。还有一个“输入”列,它只是 WHERE 子句中指定的输入字符串的副本。请注意,形式为“input=?”的约束 必须出现在 WHERE 子句中,否则虚拟表将没有要标记化的输入并且不会返回任何行。上面的示例生成以下输出:
thi|0|4|0 is|5|7|1 a|8|9|2 test|10|14|3 sentenc|15|23|4
请注意,来自 fts3tokenize 虚拟表的结果集中的标记已根据分词器的规则进行了转换。由于此示例使用了“porter”标记生成器,因此“This”标记被转换为“thi”。如果需要令牌的原始文本,可以使用带有 substr()函数的“开始”和“结束”列来检索它。例如:
SELECT substr(input, start+1, end-start), token, position FROM tok1 WHERE input='This is a test sentence.';
fts3tokenize 虚拟表可用于任何分词器,无论是否存在实际使用该分词器的 FTS3 或 FTS4 表。
9.数据结构
本节简要介绍 FTS 模块在数据库中存储其索引和内容的方式。无需阅读或理解本节中的材料即可在应用程序中使用FTS 。但是,对于尝试分析和理解 FTS 性能特征的应用程序开发人员,或者对于考虑增强现有 FTS 功能集的开发人员来说,它可能很有用。
9.1. 影子表
对于数据库中的每个 FTS 虚拟表,都会创建三到五个真实(非虚拟)表来存储底层数据。这些真实的表被称为“影子表”。真实表被命名为“%_content”、“%_segdir”、“%_segments”、“%_stat”和“%_docsize”,其中“%”被替换为 FTS 虚拟表的名称。
“%_content”表最左边的列是一个名为“docid”的 INTEGER PRIMARY KEY 字段。接下来是用户声明的 FTS 虚拟表的每一列的一列,通过在用户提供的列名前加上“c N ”来命名,其中N是表中列的索引,从左开始编号从 0 开始向右。作为虚拟表声明的一部分提供的数据类型不用作 %_content 表声明的一部分。例如:
-- Virtual table declaration CREATE VIRTUAL TABLE abc USING fts4(a NUMBER, b TEXT, c); -- Corresponding %_content table declaration CREATE TABLE abc_content(docid INTEGER PRIMARY KEY, c0a, c1b, c2c);
%_content 表包含用户插入到 FTS 虚拟表中的纯数据。如果用户在插入记录时没有明确提供“docid”值,系统会自动选择一个。
仅当 FTS 表使用 FTS4 模块而不是 FTS3 时,才会创建 %_stat 和 %_docsize 表。此外,如果 FTS4 表是使用指定为 CREATE VIRTUAL TABLE 语句的一部分的“matchinfo=fts3”指令创建的,则将省略 %_docsize 表。如果创建了,两个表的schema如下:
CREATE TABLE %_stat( id INTEGER PRIMARY KEY, value BLOB ); CREATE TABLE %_docsize( docid INTEGER PRIMARY KEY, size BLOB );
对于 FTS 表中的每一行,%_docsize 表包含具有相同“docid”值的对应行。“size”字段包含一个由N FTS varints 组成的 blob,其中N是表中用户定义的列数。“大小”blob 中的每个 varint 是 FTS 表中关联行的相应列中的标记数。%_stat 表始终包含一行,其中“id”列设置为 0。“value”列包含一个由N+1 FTS varints 组成的 blob,其中N 又是 FTS 表中用户定义的列数。blob 中的第一个 varint 设置为 FTS 表中的总行数。第二个和后续的 varint 包含存储在 FTS 表所有行的相应列中的标记总数。
剩下的两个表 %_segments 和 %_segdir 用于存储全文索引。从概念上讲,这个索引是一个查找表,它将每个术语(单词)映射到与 %_content 表中包含该术语一次或多次出现的记录对应的一组 docid 值。为了检索包含指定术语的所有文档,FTS 模块查询此索引以确定包含该术语的记录的 docid 值集,然后从 %_content 表中检索所需的文档。无论 FTS 虚拟表的架构如何,%_segments 和 %_segdir 表始终按如下方式创建:
CREATE TABLE %_segments( blockid INTEGER PRIMARY KEY, -- B-tree node id block blob -- B-tree node data ); CREATE TABLE %_segdir( level INTEGER, idx INTEGER, start_block INTEGER, -- Blockid of first node in %_segments leaves_end_block INTEGER, -- Blockid of last leaf node in %_segments end_block INTEGER, -- Blockid of last node in %_segments root BLOB, -- B-tree root node PRIMARY KEY(level, idx) );
上面描述的模式不是为了直接存储全文索引而设计的。相反,它用于存储一个或多个 b 树结构。%_segdir 表中的每一行都有一个 b 树。%_segdir 表行包含根节点和与 b 树结构关联的各种元数据,%_segments 表包含所有其他(非根)b 树节点。每个 b-tree 被称为一个“段”。一旦创建,段 B 树就永远不会更新(尽管它可能会被完全删除)。
每个段 b-tree 使用的键是术语(单词)。除了键之外,每个段 b-tree 条目都有一个关联的“doclist”(文档列表)。文档列表由零个或多个条目组成,其中每个条目包括:
- 一个 docid(文档 id),和
- 术语偏移列表,文档中每次出现该术语。术语偏移量表示在相关术语之前出现的标记(单词)的数量,而不是字符或字节的数量。比如“祖传战”这句话中“战”字的词偏移。是 3。
文档列表中的条目按 docid 排序。文档列表条目中的位置按升序存储。
逻辑全文索引的内容是通过合并所有段 b 树的内容找到的。如果一个术语出现在多个段 b-tree 中,则它映射到每个单独的 doclist 的联合。如果对于单个术语,相同的 docid 出现在多个 doclist 中,则只有作为最近创建的段 b-tree 的一部分的 doclist 被认为是有效的。
使用多个 b-tree 结构而不是单个 b-tree 来减少将记录插入 FTS 表的成本。当一条新记录插入到一个已经包含大量数据的 FTS 表中时,很可能新记录中的许多术语已经存在于大量现有记录中。如果使用单个 b-tree,则必须从数据库加载大型 doclist 结构,修改以包含新的 docid 和 term-offset 列表,然后写回数据库。使用多个 b-tree 表可以通过创建一个新的 b-tree 来避免这种情况,该 b-tree 可以在以后与现有的 b-tree(或多个 b-trees)合并。合并 b-tree 结构可以作为后台任务执行,或者一旦累积了一定数量的单独 b-tree 结构。当然,
9.2. 可变长度整数 (varint) 格式
作为段 b 树节点的一部分存储的整数值使用 FTS varint 格式进行编码。这种编码类似于SQLite varint 格式,但不完全相同。
编码的 FTS varint 占用 1 到 10 个字节的空间。所需的字节数由编码的整数值的符号和大小决定。更准确地说,用于存储编码整数的字节数取决于整数值的 64 位二进制补码表示中最高有效位的位置。负值总是设置最高有效位(符号位),因此总是使用完整的十个字节存储。可以使用更少的空间存储正整数值。
编码的 FTS varint 的最后一个字节的最高有效位被清除。所有前面的字节都设置了最高有效位。数据存储在每个字节的剩余七个最低有效位中。编码表示的第一个字节包含编码整数值的最低有效七位。编码表示的第二个字节(如果存在)包含整数值的下七个最低有效位,依此类推。下表包含编码整数值的示例:
| Decimal | Hexadecimal | Encoded Representation |
|---|---|---|
| 43 | 0x000000000000002B | 0x2B |
| 200815 | 0x000000000003106F | 0xEF 0xA0 0x0C |
| -1 | 0xFFFFFFFFFFFFFFFF | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0x01 |
9.3. 段 B 树格式
段 b-树是前缀压缩的 b+-树。%_segdir 表中的每一行都有一个段 b 树(见上文)。段 b 树的根节点作为 blob 存储在 %_segdir 表相应行的“root”字段中。所有其他节点(如果存在)都存储在 %_segments 表的“blob”列中。%_segments 表中的节点由相应行的 blockid 字段中的整数值标识。下表描述了 %_segdir 表的字段:
| Column | Interpretation |
|---|---|
| level | Between them, the contents of the "level" and "idx" fields define the relative age of the segment b-tree. The smaller the value stored in the "level" field, the more recently the segment b-tree was created. If two segment b-trees are of the same "level", the segment with the larger value stored in the "idx" column is more recent. The PRIMARY KEY constraint on the %_segdir table prevents any two segments from having the same value for both the "level" and "idx" fields. |
| idx | See above. |
| start_block | The blockid that corresponds to the node with the smallest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. If it exists, this node is always a leaf node. |
| leaves_end_block | The blockid that corresponds to the leaf node with the largest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. |
| end_block |
This field may contain either an integer or a text field consisting of
two integers separated by a space character (unicode codepoint 0x20).
The first, or only, integer is the blockid that corresponds to the interior node with the largest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. If it exists, this node is always an interior node. The second integer, if it is present, is the aggregate size of all data stored on leaf pages in bytes. If the value is negative, then the segment is the output of an unfinished incremental-merge operation, and the absolute value is current size in bytes. |
| root | Blob containing the root node of the segment b-tree. |
除了根节点之外,构成单段 B 树的节点始终使用连续的 blockid 序列存储。此外,构成单层 b 树的节点本身以 b 树顺序存储为连续块。用于存储 b-tree 叶子的连续 blockid 序列从存储在相应 %_segdir 行的“start_block”列中的 blockid 值开始分配,并以存储在相同行的“leaves_end_block”字段中的 blockid 值结束排。因此,可以通过从“start_block”到“leaves_end_block”的 blockid 顺序遍历 %_segments 表,以键顺序遍历段 b 树的所有叶子。
9.3.1. 分段 B 树叶节点
下图描述了段 b 树叶节点的格式。
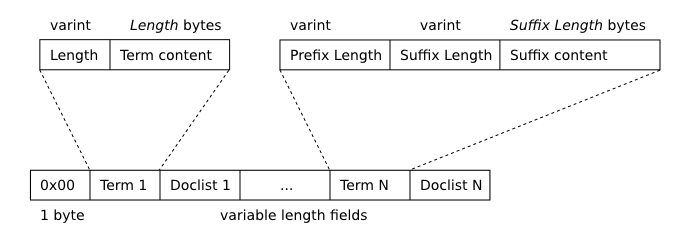
段 B-Tree 叶节点格式
每个节点上存储的第一个术语(上图中的“Term 1”)是逐字存储的。每个后续术语都相对于其前身进行了前缀压缩。术语以排序 (memcmp) 顺序存储在页面中。
9.3.2. 段 B-Tree 内部节点
下图描述了段 b 树内部(非叶)节点的格式。
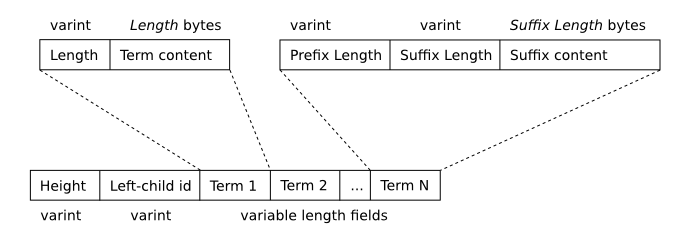
段 B-Tree 内部节点格式
9.4. 文档列表格式
doclist 由一组 64 位有符号整数组成,使用 FTS varint 格式序列化。每个 doclist 条目由一系列两个或多个整数组成,如下所示:
- 文档值。doclist 中的第一个条目包含文字 docid 值。每个后续 doclist 条目的第一个字段包含新 docid 与前一个 docid 之间的差异(始终为正数)。
- 零个或多个术语偏移列表。包含术语的 FTS 虚拟表的每一列都存在一个术语偏移列表。术语偏移列表包括以下内容:
- 常量值 1。对于与列 0 关联的任何术语偏移列表,此字段将被省略。
- 列号(1 代表最左边的第二列,等等)。对于与第 0 列关联的任何术语偏移列表,此字段将被省略。
- 术语偏移列表,从小到大排序。不是按字面意思存储术语偏移值,而是存储的每个整数是当前术语偏移与前一个之间的差值(如果当前术语偏移是第一个,则为零)加 2。
- 常数值 0。

FTS3 文档列表格式
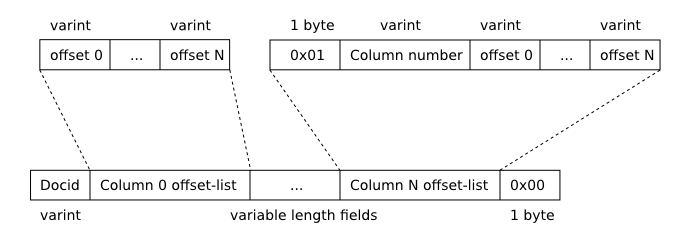
FTS 文档列表条目格式
对于术语出现在 FTS 虚拟表的多个列中的文档列表,文档列表中的术语偏移列表按列号顺序存储。这确保了与第 0 列(如果有的话)关联的术语偏移列表始终位于第一个,从而在这种情况下允许省略术语偏移列表的前两个字段。
10.限制
10.1. UTF-16字节顺序标记问题
对于 UTF-16 数据库,当使用“简单”标记器时,可能会使用格式错误的 unicode 字符串导致 完整性检查特殊命令错误地报告损坏,或者辅助函数返回不正确的结果。更具体地说,该错误可以由以下任何一种情况触发:UTF-16 字节顺序标记 (BOM) 嵌入在插入到 FTS3 表中的 SQL 字符串文字值的开头。例如:
INSERT INTO fts_table(col) VALUES(char(0xfeff)||'text...');
SQLite 转换为 UTF-16 字节顺序标记的格式错误的 UTF-8 嵌入在插入到 FTS3 表中的 SQL 字符串文字值的开头。
通过转换以两个字节 0xFF 和 0xFE 开头的 blob 创建的文本值,以任何可能的顺序插入到 FTS3 表中。例如:
INSERT INTO fts_table(col) VALUES(CAST(X'FEFF' AS TEXT));
- 数据库编码为UTF-8 。
- 所有文本字符串都是使用sqlite3_bind_text()函数系列之一插入 的。
- 文字字符串不包含字节顺序标记。
- 使用标记器将字节顺序标记识别为空格。(FTS3/4 的默认“简单”分词器不认为 BOM 是空白,但 unicode 分词器认为是。)
附录 A:搜索应用程序提示
FTS 主要设计用于支持布尔全文查询 - 用于查找符合指定条件的文档集的查询。然而,许多(大多数?)搜索应用程序要求结果以某种方式按照“相关性”排序,其中“相关性”定义为执行搜索的用户对返回文档集中的特定元素感兴趣的可能性. 当使用搜索引擎在万维网上查找文档时,用户希望最有用或“相关”的文档将作为结果的第一页返回,而随后的每一页都包含越来越不相关的结果。机器究竟如何根据用户查询确定文档相关性是一个复杂的问题,也是许多正在进行的研究的主题。
一个非常简单的方案可能是计算每个结果文档中用户搜索词的实例数。那些包含许多术语实例的文档被认为比每个术语都有少量实例的文档更相关。在 FTS 应用程序中,每个结果中的项实例数可以通过计算偏移函数返回值中的整数数来确定。以下示例显示了一个查询,该查询可用于获取用户输入的查询的十个最相关的结果:
-- This example (and all others in this section) assumes the following schema CREATE VIRTUAL TABLE documents USING fts3(title, content); -- Assuming the application has supplied an SQLite user function named "countintegers" -- that returns the number of space-separated integers contained in its only argument, -- the following query could be used to return the titles of the 10 documents that contain -- the greatest number of instances of the users query terms. Hopefully, these 10 -- documents will be those that the users considers more or less the most "relevant". SELECT title FROM documents WHERE documents MATCH <query> ORDER BY countintegers(offsets(documents)) DESC LIMIT 10 OFFSET 0
通过使用 FTS matchinfo 函数确定每个结果中出现的查询词实例的数量, 可以使上面的查询运行得更快。matchinfo 函数比 offsets 函数更有效。此外,matchinfo 函数提供了关于每个查询词在整个文档集中(不仅仅是当前行)出现的总次数以及每个查询词出现的文档数的额外信息。这可以用于(例如)将更高的权重附加到不太常见的术语,这可以增加用户认为更有趣的那些结果的总体计算相关性。
-- If the application supplies an SQLite user function called "rank" that -- interprets the blob of data returned by matchinfo and returns a numeric -- relevancy based on it, then the following SQL may be used to return the -- titles of the 10 most relevant documents in the dataset for a users query. SELECT title FROM documents WHERE documents MATCH <query> ORDER BY rank(matchinfo(documents)) DESC LIMIT 10 OFFSET 0
上例中的 SQL 查询比本节中的第一个示例使用更少的 CPU,但仍然存在不明显的性能问题。SQLite 在对结果进行排序和限制之前,通过从 FTS 模块中检索用户查询匹配的每一行的“title”列的值和 matchinfo 数据来满足此查询。由于 SQLite 虚拟表接口的工作方式,检索“title”列的值需要从磁盘加载整行(包括“content”字段,它可能非常大)。这意味着如果用户查询匹配几千个文档,许多兆字节的“标题”和“内容”数据可能会从磁盘加载到内存中,即使它们永远不会用于任何目的。
以下示例块中的 SQL 查询是此问题的一种解决方案。在 SQLite 中,当连接中使用的子查询包含 LIMIT 子句时,子查询的结果在执行主查询之前计算并存储在临时表中。这意味着 SQLite 只会将与用户查询匹配的每一行的 docid 和 matchinfo 数据加载到内存中,确定与最相关的十个文档对应的 docid 值,然后仅加载这 10 个文档的标题和内容信息。因为 matchinfo 和 docid 值都是完全从全文索引中收集的,所以从数据库加载到内存中的数据会大大减少。
SELECT title FROM documents JOIN (
SELECT docid, rank(matchinfo(documents)) AS rank
FROM documents
WHERE documents MATCH <query>
ORDER BY rank DESC
LIMIT 10 OFFSET 0
) AS ranktable USING(docid)
ORDER BY ranktable.rank DESC
下一个 SQL 块通过解决在使用 FTS 开发搜索应用程序时可能出现的另外两个问题来增强查询:
-
snippet函数不能与上述查询一起使用 。由于外部查询不包含“WHERE ... MATCH”子句,因此可能无法使用代码段函数。一种解决方案是在外部查询中复制子查询使用的 WHERE 子句。与此相关的开销通常可以忽略不计。
-
文档的相关性可能取决于除 matchinfo 返回值中可用数据之外的其他因素。例如,数据库中的每个文档都可以根据与其内容无关的因素(来源、作者、年龄、参考文献数量等)分配静态权重。这些值可以由应用程序存储在一个单独的表中,该表可以与子查询中的文档表连接,以便排名函数可以访问它们。
此版本的查询与sqlite.org 文档搜索应用程序 使用的查询非常相似 。
-- This table stores the static weight assigned to each document in FTS table
-- "documents". For each row in the documents table there is a corresponding row
-- with the same docid value in this table.
CREATE TABLE documents_data(docid INTEGER PRIMARY KEY, weight);
-- This query is similar to the one in the block above, except that:
--
-- 1. It returns a "snippet" of text along with the document title for display. So
-- that the snippet function may be used, the "WHERE ... MATCH ..." clause from
-- the sub-query is duplicated in the outer query.
--
-- 2. The sub-query joins the documents table with the document_data table, so that
-- implementation of the rank function has access to the static weight assigned
-- to each document.
SELECT title, snippet(documents) FROM documents JOIN (
SELECT docid, rank(matchinfo(documents), documents_data.weight) AS rank
FROM documents JOIN documents_data USING(docid)
WHERE documents MATCH <query>
ORDER BY rank DESC
LIMIT 10 OFFSET 0
) AS ranktable USING(docid)
WHERE documents MATCH <query>
ORDER BY ranktable.rank DESC
上面的所有示例查询都会返回十个最相关的查询结果。通过修改与 OFFSET 和 LIMIT 子句一起使用的值,可以很容易地构造返回(比方说)下十个最相关结果的查询。这可用于获取搜索应用程序第二页和后续结果页所需的数据。
下一个块包含一个示例排名函数,该函数使用在 C 中实现的 matchinfo 数据。它允许在外部为每个文档的每一列分配一个权重,而不是单个权重。它可以像使用sqlite3_create_function的任何其他用户函数一样在 SQLite 中注册。
安全警告:因为它只是一个普通的 SQL 函数,rank() 可以在任何上下文中作为任何 SQL 查询的一部分被调用。这意味着传递的第一个参数可能不是有效的 matchinfo blob。实施者应该注意处理这种情况,而不会导致缓冲区溢出或其他潜在的安全问题。
/*
** SQLite user defined function to use with matchinfo() to calculate the
** relevancy of an FTS match. The value returned is the relevancy score
** (a real value greater than or equal to zero). A larger value indicates
** a more relevant document.
**
** The overall relevancy returned is the sum of the relevancies of each
** column value in the FTS table. The relevancy of a column value is the
** sum of the following for each reportable phrase in the FTS query:
**
** (<hit count> / <global hit count>) * <column weight>
**
** where <hit count> is the number of instances of the phrase in the
** column value of the current row and <global hit count> is the number
** of instances of the phrase in the same column of all rows in the FTS
** table. The <column weight> is a weighting factor assigned to each
** column by the caller (see below).
**
** The first argument to this function must be the return value of the FTS
** matchinfo() function. Following this must be one argument for each column
** of the FTS table containing a numeric weight factor for the corresponding
** column. Example:
**
** CREATE VIRTUAL TABLE documents USING fts3(title, content)
**
** The following query returns the docids of documents that match the full-text
** query <query> sorted from most to least relevant. When calculating
** relevance, query term instances in the 'title' column are given twice the
** weighting of those in the 'content' column.
**
** SELECT docid FROM documents
** WHERE documents MATCH <query>
** ORDER BY rank(matchinfo(documents), 1.0, 0.5) DESC
*/
static void rankfunc(sqlite3_context *pCtx, int nVal, sqlite3_value **apVal){
int *aMatchinfo; /* Return value of matchinfo() */
int nMatchinfo; /* Number of elements in aMatchinfo[] */
int nCol = 0; /* Number of columns in the table */
int nPhrase = 0; /* Number of phrases in the query */
int iPhrase; /* Current phrase */
double score = 0.0; /* Value to return */
assert( sizeof(int)==4 );
/* Check that the number of arguments passed to this function is correct.
** If not, jump to wrong_number_args. Set aMatchinfo to point to the array
** of unsigned integer values returned by FTS function matchinfo. Set
** nPhrase to contain the number of reportable phrases in the users full-text
** query, and nCol to the number of columns in the table. Then check that the
** size of the matchinfo blob is as expected. Return an error if it is not.
*/
if( nVal<1 ) goto wrong_number_args;
aMatchinfo = (unsigned int *)sqlite3_value_blob(apVal[0]);
nMatchinfo = sqlite3_value_bytes(apVal[0]) / sizeof(int);
if( nMatchinfo>=2 ){
nPhrase = aMatchinfo[0];
nCol = aMatchinfo[1];
}
if( nMatchinfo!=(2+3*nCol*nPhrase) ){
sqlite3_result_error(pCtx,
"invalid matchinfo blob passed to function rank()", -1);
return;
}
if( nVal!=(1+nCol) ) goto wrong_number_args;
/* Iterate through each phrase in the users query. */
for(iPhrase=0; iPhrase<nPhrase; iPhrase++){
int iCol; /* Current column */
/* Now iterate through each column in the users query. For each column,
** increment the relevancy score by:
**
** (<hit count> / <global hit count>) * <column weight>
**
** aPhraseinfo[] points to the start of the data for phrase iPhrase. So
** the hit count and global hit counts for each column are found in
** aPhraseinfo[iCol*3] and aPhraseinfo[iCol*3+1], respectively.
*/
int *aPhraseinfo = &aMatchinfo[2 + iPhrase*nCol*3];
for(iCol=0; iCol<nCol; iCol++){
int nHitCount = aPhraseinfo[3*iCol];
int nGlobalHitCount = aPhraseinfo[3*iCol+1];
double weight = sqlite3_value_double(apVal[iCol+1]);
if( nHitCount>0 ){
score += ((double)nHitCount / (double)nGlobalHitCount) * weight;
}
}
}
sqlite3_result_double(pCtx, score);
return;
/* Jump here if the wrong number of arguments are passed to this function */
wrong_number_args:
sqlite3_result_error(pCtx, "wrong number of arguments to function rank()", -1);
}