一、FTS5概述
FTS5 是一个 SQLite虚拟表模块,为 数据库应用程序提供 全文搜索功能。在最基本的形式中,全文搜索引擎允许用户高效地搜索大量文档,以查找包含一个或多个搜索词实例的子集。Google向万维网用户提供的搜索功能 是全文搜索引擎,因为它允许用户在网络上搜索包含例如术语“fts5”的所有文档。
要使用 FTS5,用户需要创建一个包含一列或多列的 FTS5 虚拟表。例如:
CREATE VIRTUAL TABLE email USING fts5(sender, title, body);
向用于创建 FTS5 表的 CREATE VIRTUAL TABLE 语句添加类型、约束或PRIMARY KEY声明是错误的。创建后,可以像任何其他表一样使用INSERT、UPDATE或DELETE语句填充 FTS5表。与没有 PRIMARY KEY 声明的任何其他表一样,FTS5 表有一个名为 rowid 的隐式 INTEGER PRIMARY KEY 字段。
上面的示例中没有显示的是,还有 各种选项可以作为 CREATE VIRTUAL TABLE 语句的一部分提供给 FTS5,以配置新表的各个方面。这些可用于修改 FTS5 表从文档和查询中提取术语的方式,在磁盘上创建额外的索引以加速前缀查询,或创建一个 FTS5 表作为存储在其他地方的内容的索引。
填充后,可以通过三种方式对 FTS5 表的内容执行全文查询:
- 在 SELECT 语句的 WHERE 子句中使用 MATCH 运算符,或者
- 在 SELECT 语句的 WHERE 子句中使用等号(“=”)运算符,或
- 使用表值函数语法。
如果使用 MATCH 或 = 运算符,则 MATCH 运算符左侧的表达式通常是 FTS5 表的名称( 指定 column-filter时除外)。右边的表达式必须是一个文本值,指定要搜索的术语。对于表值函数语法,要搜索的术语被指定为第一个表参数。例如:
-- Query for all rows that contain at least once instance of the term
-- "fts5" (in any column). The following three queries are equivalent.
SELECT * FROM email WHERE email MATCH 'fts5';
SELECT * FROM email WHERE email = 'fts5';
SELECT * FROM email('fts5');
默认情况下,FTS5 全文搜索不区分大小写。与任何其他不包含 ORDER BY 子句的 SQL 查询一样,上面的示例以任意顺序返回结果。要按相关性(从最相关到最不相关)对结果进行排序,可以将 ORDER BY 添加到全文查询中,如下所示:
-- Query for all rows that contain at least once instance of the term -- "fts5" (in any column). Return results in order from best to worst -- match. SELECT * FROM email WHERE email MATCH 'fts5' ORDER BY rank;
除了匹配行的列值和 rowid 之外,应用程序还可以使用FTS5 辅助函数来检索有关匹配行的额外信息。例如,辅助函数可用于检索匹配行的列值的副本,匹配项的所有实例都被 html <b></b> 标记包围。辅助函数的调用方式与 SQLite标量函数相同,只是 FTS5 表的名称被指定为第一个参数。例如:
-- Query for rows that match "fts5". Return a copy of the "body" column
-- of each row with the matches surrounded by <b></b> tags.
SELECT highlight(email, 2, '<b>', '</b>') FROM email('fts5');
下面提供了可用辅助功能的描述,以及有关特殊“等级”列配置的更多详细 信息。自定义辅助函数也可以在 C 中实现并在 FTS5 中注册,就像自定义 SQL 函数可以在 SQLite 核心中注册一样。
除了搜索包含术语的所有行外,FTS5 还允许用户搜索包含以下内容的行:
- 以指定前缀开头的任何术语,
- “短语” - 文档中必须包含的术语序列或前缀术语才能匹配查询,
- 出现在彼此指定邻近范围内的一组术语、前缀术语或短语(这些称为“NEAR 查询”),或
- 以上任何一项的布尔组合。
通过提供更复杂的 FTS5 查询字符串作为 MATCH 运算符(或 = 运算符,或作为表值函数语法的第一个参数)右侧的文本来请求此类高级搜索。此处描述了完整的查询语法。
2.编译和使用FTS5
2.1. 构建 FTS5 作为 SQLite 的一部分
从版本 3.9.0 (2015-10-14) 开始,FTS5 作为 SQLite合并的一部分包含在内。如果使用两个 autoconf 构建系统之一,则通过在运行配置脚本时指定“--enable-fts5”选项来启用 FTS5。(FTS5 当前默认禁用源树配置脚本,默认启用合并配置脚本,但这些默认值将来可能会更改。)
或者,如果 sqlite3.c 是使用其他构建系统编译的,则通过安排定义 SQLITE_ENABLE_FTS5 预处理器符号。
2.2. 构建可加载扩展
或者,可以将 FTS5 构建为可加载扩展。
规范的 FTS5 源代码由 SQLite 源代码树的“ext/fts5”目录中的一系列 *.c 和其他文件组成。构建过程将其减少到只有两个文件——“fts5.c”和“fts5.h”——可用于构建 SQLite 可加载扩展。
- 从 fossil 获取最新的 SQLite 代码。
- 按照如何编译 SQLite中的描述创建 Makefile 。
- 构建“fts5.c”目标。这也创建了 fts5.h。
$ wget -c http://www.sqlite.org/src/tarball/SQLite-trunk.tgz?uuid=trunk -O SQLite-trunk.tgz .... output ... $ tar -xzf SQLite-trunk.tgz $ cd SQLite-trunk $ ./configure && make fts5.c ... lots of output ... $ ls fts5.[ch] fts5.c fts5.h
“fts5.c”中的代码然后可以编译成可加载扩展或静态链接到应用程序中,如 编译可加载扩展中所述。定义了两个入口点,它们都做同样的事情:
- sqlite3_fts_init
- sqlite3_fts5_init
编译 FTS5 扩展不需要另一个文件“fts5.h”。它由实现自定义 FTS5 分词器或辅助功能的应用程序使用。
3.全文查询语法
以下块包含 BNF 形式的 FTS 查询语法摘要。详细说明如下。
<phrase> := string [*]
<phrase> := <phrase> + <phrase>
<neargroup> := NEAR ( <phrase> <phrase> ... [, N] )
<query> := [ [-] <colspec> :] [^] <phrase>
<query> := [ [-] <colspec> :] <neargroup>
<query> := [ [-] <colspec> :] ( <query> )
<query> := <query> AND <query>
<query> := <query> OR <query>
<query> := <query> NOT <query>
<colspec> := colname
<colspec> := { colname1 colname2 ... }
3.1. FTS5 字符串
在 FTS 表达式中,可以通过以下两种方式之一指定 字符串:
-
通过将其括在双引号 (") 中。在字符串中,任何嵌入的双引号字符都可以通过添加第二个双引号字符进行 SQL 样式的转义。
-
作为不是“AND”、“OR”或“NOT”(区分大小写)的 FTS5 裸词。FTS5 裸字是由一个或多个连续字符组成的字符串,这些字符都是:
- 非 ASCII 范围字符(即大于 127 的 unicode 代码点),或
- 52 个大写和小写 ASCII 字符之一,或
- 10 个十进制数字 ASCII 字符之一,或
- 下划线字符(unicode 代码点 96)。
- 替换字符(unicode 代码点 26)。
3.2. FTS5 短语
FTS 查询由短语组成。短语是一个或多个标记的有序列表。通过将字符串传递给 FTS 表分词器,将字符串转换为短语。可以使用“+”运算符将两个短语连接成一个大短语。例如,假设正在使用的标记器模块将输入“one.two.three”标记为三个单独的标记,以下四个查询都指定了相同的短语:
... MATCH '"one two three"' ... MATCH 'one + two + three' ... MATCH '"one two" + three' ... MATCH 'one.two.three'
如果文档包含至少一个与构成该短语的标记序列相匹配的标记子序列,则该短语与该文档相匹配。
3.3. FTS5 前缀查询
如果“*”字符跟在 FTS 表达式中的字符串之后,那么从字符串中提取的最终标记将被标记为前缀标记。如您所料,前缀标记匹配任何以它为前缀的文档标记。例如,以下块中的前两个查询将匹配包含标记“one”的任何文档,紧接着是标记“two”,然后是任何以“thr”开头的标记。
... MATCH '"one two thr" * ' ... MATCH 'one + two + thr*' ... MATCH '"one two thr*"' -- May not work as expected!
上面块中的最终查询可能无法按预期工作。因为“*”字符在双引号内,它会被传递给分词器,分词器可能会丢弃它(或者,根据使用的特定分词器,可能将其作为最终分词的一部分)而不是识别它作为一个特殊的 FTS 字符。
3.4. FTS5 初始令牌查询
如果“^”字符紧接在不属于 NEAR 查询的短语之前出现,则该短语仅在它从列中的第一个标记开始时才匹配文档。“^”语法可以与 列过滤器结合使用,但不能插入短语的中间。
... MATCH '^one' -- first token in any column must be "one" ... MATCH '^ one + two' -- phrase "one two" must appear at start of a column ... MATCH '^ "one two"' -- same as previous ... MATCH 'a : ^two' -- first token of column "a" must be "two" ... MATCH 'NEAR(^one, two)' -- syntax error! ... MATCH 'one + ^two' -- syntax error! ... MATCH '"^one two"' -- May not work as expected!
3.5. FTS5 近查询
两个或更多的短语可以被分组到一个NEAR 组中。NEAR 组由标记“NEAR”(区分大小写)指定,后跟一个左括号字符,后跟两个或多个空格分隔的短语,可选地后跟一个逗号和数字参数N,然后是一个右括号。例如:
... MATCH 'NEAR("one two" "three four", 10)'
... MATCH 'NEAR("one two" thr* + four)'
如果未提供N参数,则默认为 10。如果文档至少包含一组标记,则 NEAR 组与文档匹配:
- 每个短语至少包含一个实例,并且
- 其中第一个短语结尾和最后一个短语开头之间的标记数小于或等于N。
例如:
CREATE VIRTUAL TABLE f USING fts5(x);
INSERT INTO f(rowid, x) VALUES(1, 'A B C D x x x E F x');
... MATCH 'NEAR(e d, 4)'; -- Matches!
... MATCH 'NEAR(e d, 3)'; -- Matches!
... MATCH 'NEAR(e d, 2)'; -- Does not match!
... MATCH 'NEAR("c d" "e f", 3)'; -- Matches!
... MATCH 'NEAR("c" "e f", 3)'; -- Does not match!
... MATCH 'NEAR(a d e, 6)'; -- Matches!
... MATCH 'NEAR(a d e, 5)'; -- Does not match!
... MATCH 'NEAR("a b c d" "b c" "e f", 4)'; -- Matches!
... MATCH 'NEAR("a b c d" "b c" "e f", 3)'; -- Does not match!
3.6. FTS5 柱过滤器
单个短语或 NEAR 组可以限制为匹配 FTS 表的指定列中的文本,方法是在列名前加上冒号字符作为前缀。或者通过在一组列前面加上一个空格分隔的列名列表作为前缀,列名括在括号(“大括号”)中,后跟一个冒号字符。可以使用上面针对字符串描述的两种形式中的任何一种来指定列名。与作为短语一部分的字符串不同,列名不会传递给分词器模块。对于 SQLite 列名,列名通常不区分大小写 - 只有 ASCII 范围字符才能理解大写/小写等价。
... MATCH 'colname : NEAR("one two" "three four", 10)'
... MATCH '"colname" : one + two + three'
... MATCH '{col1 col2} : NEAR("one two" "three four", 10)'
... MATCH '{col2 col1 col3} : one + two + three'
如果列过滤器规范前面有“-”字符,则它被解释为不匹配的列列表。例如:
-- Search for matches in all columns except "colname"
... MATCH '- colname : NEAR("one two" "three four", 10)'
-- Search for matches in all columns except "col1", "col2" and "col3"
... MATCH '- {col2 col1 col3} : one + two + three'
列过滤器规范也可以应用于括号中的任意表达式。在这种情况下,列过滤器适用于表达式中的所有短语。嵌套列过滤操作只能进一步限制匹配列的子集,它们不能用于重新启用过滤列。例如:
-- The following are equivalent:
... MATCH '{a b} : ( {b c} : "hello" AND "world" )'
... MATCH '(b : "hello") AND ({a b} : "world")'
最后,可以通过使用列名作为 MATCH 运算符的 LHS(而不是通常的表名)来指定单个列的列过滤器。例如:
-- Given the following table CREATE VIRTUAL TABLE ft USING fts5(a, b, c); -- The following are equivalent SELECT * FROM ft WHERE b MATCH 'uvw AND xyz'; SELECT * FROM ft WHERE ft MATCH 'b : (uvw AND xyz)'; -- This query cannot match any rows (since all columns are filtered out): SELECT * FROM ft WHERE b MATCH 'a : xyz';
3.7. FTS5 布尔运算符
短语和 NEAR 组可以使用布尔运算符排列到表达式中。按照优先顺序,从最高(最紧分组)到最低(最松分组),运算符是:
| Operator | Function |
|---|---|
<query1> NOT <query2>
| Matches if query1 matches and query2 does not match. |
<query1> AND <query2>
| Matches if both query1 and query2 match. |
<query1> OR <query2>
| Matches if either query1 or query2 match. |
括号可用于对表达式进行分组,以便以通常的方式修改运算符的优先级。例如:
-- Matches documents that contain at least one instance of either "one" -- or "two", but do not contain any instances of token "three". ... MATCH 'one OR two NOT three' -- Match all documents that contain the token "two" but not "three", or -- contain the token "one". ... MATCH 'one OR (two NOT three)'
短语和 NEAR 组也可以通过隐式 AND 运算符连接。为了简单起见,上面的 BNF 文法中没有显示这些。本质上,任何仅由空格分隔的短语或 NEAR 组(包括那些仅限于匹配指定列的序列)的处理方式就好像每对短语或 NEAR 组之间存在隐式 AND 运算符一样。隐式 AND 运算符永远不会插入到括号中的表达式之后或之前。例如:
... MATCH 'one two three' -- 'one AND two AND three' ... MATCH 'three "one two"' -- 'three AND "one two"' ... MATCH 'NEAR(one two) three' -- 'NEAR(one two) AND three' ... MATCH 'one OR two three' -- 'one OR two AND three' ... MATCH '(one OR two) three' -- Syntax error! ... MATCH 'func(one two)' -- Syntax error!
4. FTS5表创建和初始化
作为“CREATE VIRTUAL TABLE ... USING fts5 ...”语句的一部分指定的每个参数是列声明或配置选项。列 声明由一个或多个空格分隔的 FTS5 裸词或以 SQLite 可接受的任何方式引用的字符串文字组成。
列声明中的第一个字符串或裸字是列名。尝试将 fts5 表列命名为“rowid”或“rank”,或将与表本身使用的名称相同的名称分配给列是错误的。这是不支持的。
列声明中的每个后续字符串或裸字都是修改该列行为的列选项。列选项与大小写无关。与 SQLite 核心不同,FTS5 将无法识别的列选项视为错误。目前,唯一可识别的选项是 “UNINDEXED”(见下文)。
配置选项由一个FTS5 裸字(选项名称)和一个“=”字符组成,然后是选项值。选项值使用单个 FTS5 裸字或字符串文字指定,再次以 SQLite 核心可接受的任何方式引用。例如:
CREATE VIRTUAL TABLE mail USING fts5(sender, title, body, tokenize = 'porter ascii');
目前有以下配置选项:
- “tokenize”选项,用于配置自定义分词器。
- “前缀”选项,用于向 FTS5 表 添加前缀索引。
- “内容”选项,用于使 FTS5 表成为 外部内容表或无内容表。
- “content_rowid”选项,用于设置 外部内容表的rowid字段。
- “ columnsize”选项,用于配置 FTS5 表中每个值的令牌大小是否单独存储在数据库中。
- “详细信息”选项。此选项可用于通过省略一些信息来减少磁盘上 FTS 索引的大小。
4.1. UNINDEXED 列选项
使用 UNINDEXED 列选项限定的列的内容不会添加到 FTS 索引中。这意味着出于 MATCH 查询和 FTS5 辅助功能的目的,该列不包含可匹配的标记。
例如,要避免将“uuid”字段的内容添加到 FTS 索引中:
CREATE VIRTUAL TABLE customers USING fts5(name, addr, uuid UNINDEXED);
4.2. 前缀索引
默认情况下,FTS5 维护单个索引,记录文档集中每个标记实例的位置。这意味着查询完整的标记很快,因为它需要一次查找,但查询前缀标记可能很慢,因为它需要范围扫描。例如,要查询前缀标记“abc*”,需要对大于或等于“abc”且小于“abd”的所有标记进行范围扫描。
前缀索引是一个单独的索引,它记录了一定长度的前缀标记的所有实例的位置,用于加速前缀标记的查询。例如,优化前缀令牌“abc*”的查询需要三字符前缀的前缀索引。
要向 FTS5 表添加前缀索引,“前缀”选项设置为单个正整数或包含一个或多个正整数值的空格分隔列表的文本值。为每个指定的整数创建一个前缀索引。如果将多个“前缀”选项指定为单个 CREATE VIRTUAL TABLE 语句的一部分,则所有选项均适用。
-- Two ways to create an FTS5 table that maintains prefix indexes for -- two and three character prefix tokens. CREATE VIRTUAL TABLE ft USING fts5(a, b, prefix='2 3'); CREATE VIRTUAL TABLE ft USING fts5(a, b, prefix=2, prefix=3);
4.3. 分词器
CREATE VIRTUAL TABLE“tokenize”选项用于配置 FTS5 表使用的特定分词器。选项参数必须是 FTS5 裸词或 SQL 文本文字。参数的文本本身被视为一个或多个 FTS5 裸词或 SQL 文本文字的空白系列。其中第一个是要使用的分词器的名称。第二个和后续列表元素(如果存在)是传递给分词器实现的参数。
与选项值和列名不同,用作分词器的 SQL 文本文字必须使用单引号字符引用。例如:
-- The following are all equivalent CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter ascii'); CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = "porter ascii"); CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = "'porter' 'ascii'"); CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = '''porter'' ''ascii'''); -- But this will fail: CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = '"porter" "ascii"'); -- This will fail too: CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter' 'ascii');
FTS5 具有三个内置分词器模块,在后续部分中进行了描述:
- unicode61分词器,基于 Unicode 6.1 标准。这是默认设置。
- ascii分词器假定 ASCII 代码点范围 (0-127) 之外的所有字符都被视为分词字符。
- porter tokenizer,它实现了 porter词干提取算法。
也可以为 FTS5 创建自定义分词器。这样做的 API 在此处描述。
4.3.1. Unicode61 分词器
unicode 分词器将所有 unicode 字符分类为“分隔符”或“标记”字符。默认情况下,Unicode 6.1 定义的所有空格和标点字符都被视为分隔符,所有其他字符都被视为标记字符。更具体地说,分配给以 “L”或“N”(特别是字母和数字)开头的 一般类别或分配给类别“Co”(“其他,私人使用”)的所有 unicode 字符都被视为令牌。所有其他字符都是分隔符。
一个或多个令牌字符的每个连续运行都被认为是一个令牌。根据 Unicode 6.1 定义的规则,分词器不区分大小写。
默认情况下,变音符号会从所有拉丁脚本字符中删除。这意味着,例如,“A”、“a”、“À”、“à”、“”和“â”都被认为是等价的。
令牌规范中“unicode61”之后的任何参数都被视为交替选项名称和值的列表。Unicode61 支持以下选项:
| Option | Usage |
|---|---|
| remove_diacritics | This option should be set to "0", "1" or "2". The default value is "1". If it is set to "1" or "2", then diacritics are removed from Latin script characters as described above. However, if it is set to "1", then diacritics are not removed in the fairly uncommon case where a single unicode codepoint is used to represent a character with more that one diacritic. For example, diacritics are not removed from codepoint 0x1ED9 ("LATIN SMALL LETTER O WITH CIRCUMFLEX AND DOT BELOW"). This is technically a bug, but cannot be fixed without creating backwards compatibility problems. If this option is set to "2", then diacritics are correctly removed from all Latin characters. |
| categories | This option may be used to modify the set of Unicode general categories that are considered to correspond to token characters. The argument must consist of a space separated list of two-character general category abbreviations (e.g. "Lu" or "Nd"), or of the same with the second character replaced with an asterisk ("*"), interpreted as a glob pattern. The default value is "L* N* Co". |
| tokenchars | This option is used to specify additional unicode characters that should be considered token characters, even if they are white-space or punctuation characters according to Unicode 6.1. All characters in the string that this option is set to are considered token characters. |
| separators | This option is used to specify additional unicode characters that should be considered as separator characters, even if they are token characters according to Unicode 6.1. All characters in the string that this option is set to are considered separators. |
例如:
-- Create an FTS5 table that does not remove diacritics from Latin
-- script characters, and that considers hyphens and underscore characters
-- to be part of tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize = "unicode61 remove_diacritics 0 tokenchars '-_'"
);
或者:
-- Create an FTS5 table that, as well as the default token character classes,
-- considers characters in class "Mn" to be token characters.
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize = "unicode61 categories 'L* N* Co Mn'"
);
fts5 unicode61 分词器与 fts3/4 unicode61 分词器逐字节兼容。
4.3.2. Ascii 分词器
Ascii 分词器类似于 Unicode61 分词器,不同之处在于:
- 所有非 ASCII 字符(代码点大于 127 的字符)始终被视为标记字符。如果任何非 ASCII 字符被指定为分隔符选项的一部分,它们将被忽略。
- 仅对 ASCII 字符执行大小写折叠。因此,虽然“A”和“a”被认为是等价的,但“Ô和“ã”是不同的。
- 不支持 remove_diacritics 选项。
例如:
-- Create an FTS5 table that uses the ascii tokenizer, but does not
-- consider numeric characters to be part of tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize = "ascii separators '0123456789'"
);
4.3.3. 波特分词器
porter tokenizer 是一个包装器 tokenizer。它获取一些其他标记器的输出,并在 将每个标记返回到 FTS5 之前将波特词干提取算法应用于每个标记。这允许像“correction”这样的搜索词匹配类似的词,如“corrected”或“correcting”。波特词干分析器算法仅设计用于英语语言术语 - 将其用于其他语言可能会也可能不会提高搜索效用。
默认情况下,搬运工分词器作为默认分词器 (unicode61) 的包装器运行。或者,如果将一个或多个额外参数添加到“porter”之后的“tokenize”选项,它们将被视为 porter 词干分析器使用的底层分词器的规范。例如:
-- Two ways to create an FTS5 table that uses the porter tokenizer to -- stem the output of the default tokenizer (unicode61). CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = porter); CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter unicode61'); -- A porter tokenizer used to stem the output of the unicode61 tokenizer, -- with diacritics removed before stemming. CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter unicode61 remove_diacritics 1');
4.3.4. 实验性的 Trigram Tokenizer
实验性的trigram tokenizer 扩展了 FTS5 以支持一般的子字符串匹配,而不是通常的标记匹配。使用 trigram tokenizer 时,查询或短语标记可以匹配一行中的任何字符序列,而不仅仅是一个完整的标记。例如:
CREATE VIRTUAL TABLE tri USING fts5(a, tokenize="trigram");
INSERT INTO tri VALUES('abcdefghij KLMNOPQRST uvwxyz');
-- The following queries all match the single row in the table
SELECT * FROM tri('cdefg');
SELECT * FROM tri('cdefg AND pqr');
SELECT * FROM tri('"hij klm" NOT stuv');
trigram tokenizer 支持一个选项——“case_sensitive”。使用默认值 0,匹配不区分大小写。如果此值设置为 1,则所有匹配项都区分大小写。
-- A case-sensitive trigram index CREATE VIRTUAL TABLE tri USING fts5(a, tokenize="trigram case_sensitive 1");
使用 trigram tokenizer 的 FTS5 表还支持索引 GLOB 和 LIKE 模式匹配。例如:
SELECT * FROM tri WHERE a LIKE '%cdefg%'; SELECT * FROM tri WHERE a GLOB '*ij klm*xyz';
如果在将 case_sensitive 选项设置为 1 的情况下创建 FTS5 trigram tokenizer,它可能只会索引 GLOB 查询,而不是 LIKE。
笔记:
- 与全文查询一起使用时,由少于 3 个 unicode 字符组成的子字符串不匹配任何行。如果 LIKE 或 GLOB 模式不包含至少一个非通配符 unicode 字符序列,则 FTS5 回退到对整个表进行线性扫描。
- 如果 FTS5 表是使用指定的 detail=none 或 detail=column 选项创建的,则全文查询可能不包含任何超过 3 个 unicode 字符的标记。LIKE 和 GLOB 模式匹配可能稍微慢一些,但仍然有效。如果索引仅用于 LIKE 和/或 GLOB 模式匹配,这些选项值得尝试以减少索引大小。
4.4. 外部内容和无内容表
通常,当一行被插入 FTS5 表时,以及各种全文索引条目和其他数据,该行的副本存储在由 FTS5 模块管理的私有表中。当用户或辅助函数实现从 FTS5 表中请求列值时,将从该私有表中读取它们。“内容”选项可用于创建仅存储 FTS 全文索引条目的 FTS5 表。因为列值本身通常比关联的全文索引条目大得多,所以这可以节省大量数据库空间。
有两种使用“内容”选项的方法:
- 通过将其设置为空字符串来创建无内容的 FTS5 表。在这种情况下,FTS5 假定原始列值在处理查询时不可用。仍然可以使用全文查询和一些辅助功能,但不能从表中读取除 rowid 之外的列值。
- 通过将其设置为 FTS5 可以随时查询以检索列值的数据库对象(表、虚拟表或视图)的名称。这称为“外部内容”表。在这种情况下,可以使用所有 FTS5 功能,但用户有责任确保全文索引的内容与指定的数据库对象一致。如果不是,查询结果可能无法预测。
4.4.1. 无内容的表格
通过将“内容”选项设置为空字符串来创建无内容的 FTS5 表。例如:
CREATE VIRTUAL TABLE f1 USING fts5(a, b, c, content='');
无内容的 FTS5 表不支持 UPDATE 或 DELETE 语句,或不为 rowid 字段提供非 NULL 值的 INSERT 语句。无内容表不支持 REPLACE 冲突处理。REPLACE 和 INSERT OR REPLACE 语句被视为常规 INSERT 语句。可以使用FTS5 删除命令从无内容表中删除行。
尝试从无内容的 FTS5 表中读取除 rowid 之外的任何列值将返回 SQL NULL 值。
4.4.2. 外部目录
外部内容 FTS5 表是通过将内容选项设置为同一数据库中的表、虚拟表或视图(以下简称“内容表”)的名称来创建的。每当 FTS5 需要列值时,它都会按如下方式查询内容表,并将需要值的行的 rowid 绑定到 SQL 变量:
SELECT <content_rowid>, <cols> FROM <content> WHERE <content_rowid> = ?;
在上面,<content> 替换为内容表的名称。默认情况下,<content_rowid> 替换为文字文本“rowid”。或者,如果在 CREATE VIRTUAL TABLE 语句中设置了“content_rowid”选项,则由该选项的值设置。<cols> 替换为以逗号分隔的 FTS5 表列名称列表。例如:
-- If the database schema is: CREATE TABLE tbl (a, b, c, d INTEGER PRIMARY KEY); CREATE VIRTUAL TABLE fts USING fts5(a, c, content=tbl, content_rowid=d); -- Fts5 may issue queries such as: SELECT d, a, c FROM tbl WHERE d = ?;
也可以按如下方式查询内容表:
SELECT <content_rowid>, <cols> FROM <content> ORDER BY <content_rowid> ASC; SELECT <content_rowid>, <cols> FROM <content> ORDER BY <content_rowid> DESC;
确保外部内容 FTS5 表的内容与内容表保持同步仍然是用户的责任。一种方法是使用触发器。例如:
-- Create a table. And an external content fts5 table to index it.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, b, c);
CREATE VIRTUAL TABLE fts_idx USING fts5(b, c, content='tbl', content_rowid='a');
-- Triggers to keep the FTS index up to date.
CREATE TRIGGER tbl_ai AFTER INSERT ON tbl BEGIN
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
CREATE TRIGGER tbl_ad AFTER DELETE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c) VALUES('delete', old.a, old.b, old.c);
END;
CREATE TRIGGER tbl_au AFTER UPDATE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c) VALUES('delete', old.a, old.b, old.c);
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
与无内容表一样,外部内容表不支持 REPLACE 冲突处理。任何指定 REPLACE 冲突处理的操作都使用 ABORT 进行处理。
4.5. 列大小选项
通常,FTS5 在数据库中维护一个特殊的支持表,该表将插入到主 FTS5 表中的标记中的每个列值的大小存储在一个单独的表中。这个支持表由 xColumnSize API 函数使用,它又由内置的bm25 排名函数使用(并且可能对其他排名函数也有用)。
为了节省空间,可以通过将 columnsize 选项设置为零来省略此支持表。例如:
-- A table without the xColumnSize() values stored on disk: CREATE VIRTUAL TABLE ft USING fts5(a, b, c, columnsize=0); -- Three equivalent ways of creating a table that does store the -- xColumnSize() values on disk: CREATE VIRTUAL TABLE ft USING fts5(a, b, c); CREATE VIRTUAL TABLE ft USING fts5(a, b, c, columnsize=1); CREATE VIRTUAL TABLE ft USING fts5(a, b, columnsize='1', c);
将 columnsize 选项设置为 0 或 1 以外的任何值都是错误的。
如果 FTS5 表配置为 columnsize=0 但不是 无内容表,则 xColumnSize API 函数仍然有效,但运行速度要慢得多。在这种情况下,它不是读取直接从数据库返回的值,而是读取文本值本身并根据需要计算其中的标记。
或者,如果该表也是无内容表,则适用以下内容:
-
xColumnSize API 始终返回 -1。无法确定存储在配置为 columnsize=0 的无内容 FTS5 表中的值中的标记数。
-
每个插入的行都必须附有明确指定的 rowid 值。如果无内容表配置为 columnsize=0,则尝试将 NULL 值插入 rowid 是一个 SQLITE_MISMATCH 错误。
-
对表的所有查询都必须是全文查询。换句话说,它们必须使用 MATCH 或 = 运算符并将表名列作为左侧操作数,或者使用表值函数语法。任何不是全文查询的查询都会导致错误。
存储 xColumnSize 值的表的名称(除非指定了 columnsize=0)是“<name>_docsize”,其中 <name> 是 FTS5 表本身的名称。sqlite3_analyzer工具可 用于现有数据库,以确定通过使用 columnsize=0 重新创建 FTS5 表可以节省多少空间。
4.6. 细节选项
对于文档中的每个词,FTS5 维护的 FTS 索引存储文档的 rowid、包含词的列的列号以及词在列值中的偏移量。“详细信息”选项可用于省略其中的一些信息。这减少了索引在数据库文件中占用的空间,但也降低了系统的能力和效率。
detail 选项可以设置为“full”(默认值)、“column”或“none”。例如:
-- The following two lines are equivalent (because the default value -- of "detail" is "full". CREATE VIRTUAL TABLE ft1 USING fts5(a, b, c); CREATE VIRTUAL TABLE ft1 USING fts5(a, b, c, detail=full); CREATE VIRTUAL TABLE ft2 USING fts5(a, b, c, detail=column); CREATE VIRTUAL TABLE ft3 USING fts5(a, b, c, detail=none);
如果 detail 选项设置为column,那么对于每个术语,FTS 索引只记录 rowid 和列号,忽略术语偏移信息。这导致以下限制:
- NEAR 查询不可用。
- 短语查询不可用。
- 假设该表也不是 无内容表,则 xInstCount、xInst、 xPhraseFirst和xPhraseNext 比平时慢。这是因为他们必须按需加载和标记文档文本,而不是直接从 FTS 索引中读取所需的数据。
- 如果该表也是无内容表,则 xInstCount、xInst、xPhraseFirst 和 xPhraseNext API 的行为就好像当前行根本不包含任何短语匹配(即 xInstCount() 返回 0)。
如果 detail 选项设置为none,那么对于每个术语,FTS 索引记录只存储 rowid。列和偏移量信息都被省略。除了上面为 detail=column 模式逐项列出的限制外,这还施加了以下额外限制:
- 列过滤器查询不可用。
- 假设该表不是无内容表,则 xPhraseFirstColumn和 xPhraseNextColumn比平时慢。
- 如果该表也是无内容表,则 xPhraseFirstColumn 和 xPhraseNextColumn API 的行为就好像当前行根本不包含短语匹配(即 xPhraseFirstColumn() 将迭代器设置为 EOF)。
在一个索引大量电子邮件(磁盘上 1636 MiB)的测试中,FTS 索引在磁盘上为 743 MiB(详细信息=完整),340 MiB(详细信息=列)和 134 MiB(详细信息=无)。
五、辅助功能
辅助函数类似于SQL 标量函数,不同之处在于它们只能在 FTS5 表的全文查询(使用 MATCH 运算符的查询)中使用。它们的结果不仅根据传递给它们的参数计算,还根据当前匹配项和匹配行计算。例如,辅助函数可能会返回一个数值,指示匹配的准确性(请参阅bm25()函数),或者来自匹配行的包含一个或多个搜索词实例的文本片段(请参阅代码段( )功能)。
要调用辅助函数,应将 FTS5 表的名称指定为第一个参数。其他参数可能跟在第一个之后,具体取决于被调用的特定辅助函数。例如,要调用“突出显示”功能:
SELECT highlight(email, 2, '<b>', '</b>') FROM email WHERE email MATCH 'fts5'
作为 FTS5 的一部分提供的内置辅助功能将在下一节中介绍。应用程序还可以 在 C 中实现自定义辅助功能。
5.1. 内置辅助功能
FTS5提供了三个内置的辅助功能:
- bm25 () 辅助函数返回一个反映当前匹配准确度的真实值。较好的匹配被赋予较低的数值。
- highlight() 辅助函数从当前匹配的列之一返回文本的副本,结果中查询词的每个实例都被指定的标记包围(例如“<b>”和“</b>” ).
- snippet() 辅助函数从匹配行的一列中选择一小段文本,并以与 highlight() 函数相同的方式将其与被标记包围的查询术语的每个实例一起返回。选择文本片段以最大化其包含的查询术语的数量。
5.1.1. bm25() 函数
内置辅助函数 bm25() 返回一个实数值,表示当前行与全文查询的匹配程度。匹配越好,返回的值在数值上越小。可以使用如下查询按从最佳匹配到最差匹配的顺序返回匹配项:
SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts)
为了计算文档分数,全文查询被分成其组成短语。文档D和查询Q的 bm25 分数计算如下:
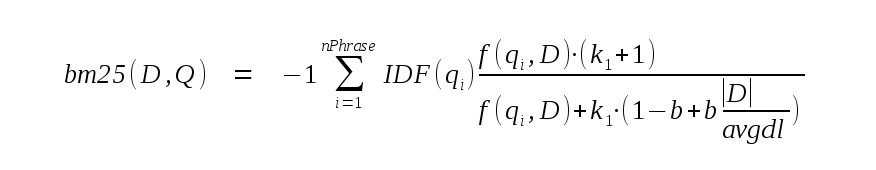
在上面,nPhrase是查询中的短语数。 |D| 是当前文档中的标记 数, avgdl是 FTS5 表中所有文档中的平均标记数。 k 1和b都是常数,分别硬编码为 1.2 和 0.75。
在 BM25 算法的大多数实现中找不到公式开头的“-1”项。没有它,更好的匹配会被分配更高的 BM25 分数。由于默认排序顺序是“升序”,这意味着将“ORDER BY bm25(fts)”附加到查询将导致结果按从最坏到最好的顺序返回。需要“DESC”关键字才能首先返回最佳匹配项。为了避免这个陷阱,BM25 的 FTS5 实现在返回结果之前将结果乘以 -1,确保更好的匹配被赋予较低的数值分数。
IDF(q i )是查询短语i的逆文档频率。它的计算方式如下,其中N是 FTS5 表中的总行数,n(q i )是包含至少一个短语i实例的总行数:

最后,f(q i ,D)是短语 i的短语频率。默认情况下,这只是当前行中短语出现的次数。但是,通过将额外的实际值参数传递给 bm25() SQL 函数,表的每一列都可以分配不同的权重,并且短语频率计算如下:
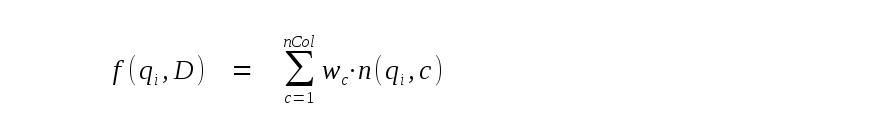
其中wc是分配给c列的权重, n(q i , c )是短语i在当前行的c列中出现的次数。表名后传递给 bm25() 的第一个参数是分配给 FTS5 表最左边列的权重。第二个是分配给最左边第二列的权重,依此类推。如果没有足够的参数用于所有表列,则剩余列的权重为 1.0。如果尾随参数太多,多余的部分将被忽略。例如:
-- Assuming the following schema: CREATE VIRTUAL TABLE email USING fts5(sender, title, body); -- Return results in bm25 order, with each phrase hit in the "sender" -- column considered the equal of 10 hits in the "body" column, and -- each hit in the "title" column considered as valuable as 5 hits in -- the "body" column. SELECT * FROM email WHERE email MATCH ? ORDER BY bm25(email, 10.0, 5.0);
有关 BM25及其变体 的更多信息,请参阅维基百科 。
5.1.2. 突出显示()功能
highlight() 函数返回当前行指定列中的文本副本,并插入额外的标记文本以标记短语匹配的开始和结束。
highlight() 必须在表名后使用恰好三个参数来调用。解释如下:
- 一个整数,指示要从中读取文本的 FTS 表列的索引。列从零开始从左到右编号。
- 在每个短语匹配之前插入的文本。
- 在每个短语匹配后插入的文本。
例如:
-- Return a copy of the text from the leftmost column of the current -- row, with phrase matches marked using html "b" tags. SELECT highlight(fts, 0, '<b>', '</b>') FROM fts WHERE fts MATCH ?
在两个或多个短语实例重叠(共享一个或多个共同标记)的情况下,将为每组重叠短语插入一个打开和关闭标记。例如:
-- Assuming this:
CREATE VIRTUAL TABLE ft USING fts5(a);
INSERT INTO ft VALUES('a b c x c d e');
INSERT INTO ft VALUES('a b c c d e');
INSERT INTO ft VALUES('a b c d e');
-- The following SELECT statement returns these three rows:
-- '[a b c] x [c d e]'
-- '[a b c] [c d e]'
-- '[a b c d e]'
SELECT highlight(ft, 0, '[', ']') FROM ft WHERE ft MATCH 'a+b+c AND c+d+e';
5.1.3. 片段()函数
snippet() 函数与 highlight() 类似,不同之处在于它不是返回整个列值,而是自动选择并提取一小段文档文本进行处理并返回。snippet() 函数必须在表名参数之后传递五个参数:
- 一个整数,指示要从中选择返回文本的 FTS 表列的索引。列从零开始从左到右编号。负值表示应自动选择该列。
- 要在返回的文本中匹配的每个短语之前插入的文本。
- 在返回文本中的每个短语匹配后插入的文本。
- 添加到所选文本的开头或结尾的文本,以指示返回的文本不会分别出现在其列的开头或结尾。
- 返回文本中的最大标记数。这必须大于零且等于或小于 64。
5.2. 按辅助功能结果排序
所有 FTS5 表都有一个名为“rank”的特殊隐藏列。如果当前查询不是全文查询(即如果它不包含 MATCH 运算符),则“rank”列的值始终为 NULL。否则,在全文查询中,列等级默认包含与执行不带尾随参数的 bm25() 辅助函数返回的值相同的值。
从排名列读取和直接在查询中使用 bm25() 函数之间的区别仅在按返回值排序时才显着。在这种情况下,使用“rank”比使用 bm25() 更快。
-- The following queries are logically equivalent. But the second may -- be faster, particularly if the caller abandons the query before -- all rows have been returned (or if the queries were modified to -- include LIMIT clauses). SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts); SELECT * FROM fts WHERE fts MATCH ? ORDER BY rank;
映射到排名列的特定辅助函数可以在每个查询的基础上配置,或者通过为 FTS 表设置不同的持久默认值来代替使用没有尾随参数的 bm25()。
为了更改单个查询的排名列的映射,在查询的 WHERE 子句中添加了类似于以下任一项的术语:
rank MATCH 'auxiliary-function-name(arg1, arg2, ...)' rank = 'auxiliary-function-name(arg1, arg2, ...)'
MATCH 或 = 运算符的右侧必须是一个常量表达式,其计算结果为一个字符串,该字符串由要调用的辅助函数组成,后跟括号内的零个或多个逗号分隔参数。参数必须是 SQL 文字。例如:
-- The following queries are logically equivalent. But the second may -- be faster. See above. SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts, 10.0, 5.0); SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)' ORDER BY rank;
表值函数语法也可用于指定替代排名函数。在这种情况下,描述排名函数的文本应指定为第二个表值函数参数。以下三个查询是等价的:
SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)' ORDER BY rank; SELECT * FROM fts WHERE fts = ? AND rank = 'bm25(10.0, 5.0)' ORDER BY rank; SELECT * FROM fts WHERE fts(?, 'bm25(10.0, 5.0)') ORDER BY rank;
可以使用FTS5 rank 配置选项修改表的 rank 列的默认映射。
6.特殊的 INSERT 命令
6.1. 'automerge' 配置选项
FTS5 没有使用磁盘上的单一数据结构来存储全文索引,而是使用了一系列 B 树。每次提交新事务时,都会将包含已提交事务内容的新 b 树写入数据库文件。当查询全文索引时,必须单独查询每个 b-tree,并在返回给用户之前合并结果。
为了防止数据库中的 b 树数量变得太大(减慢查询速度),较小的 b 树会定期合并为包含相同数据的单个较大的 b 树。默认情况下,这会在修改全文索引的 INSERT、UPDATE 或 DELETE 语句中自动发生。'automerge' 参数确定一次合并多少个较小的 b 树。将其设置为较小的值可以加快查询速度(因为它们必须查询和合并来自较少 b 树的结果),但也会减慢写入数据库的速度(因为每个 INSERT、UPDATE 或 DELETE 语句必须做更多的工作作为自动合并过程的一部分)。
组成全文索引的每个 b 树都根据其大小分配给一个“级别”。0 级 b 树是最小的,因为它们包含单个事务的内容。更高级别的 b 树是将两个或更多级别 0 b 树合并在一起的结果,因此它们更大。一旦存在M个或更多具有相同级别的 b 树,FTS5 就开始将 b 树合并在一起,其中M是“automerge”参数的值。
“automerge”参数的最大允许值为 16。默认值为 4。将“automerge”参数设置为 0 将完全禁用 b 树的自动增量合并。
INSERT INTO ft(ft, rank) VALUES('automerge', 8);
6.2. “危机合并”配置选项
'crisismerge' 选项类似于 'automerge',因为它确定组成全文索引的组件 b 树合并在一起的方式和频率。一旦全文索引中的单个级别上存在C或更多 B 树,其中C是 'crisismerge' 选项的值,该级别上的所有 B 树将立即合并为单个 B 树。
此选项与“automerge”选项之间的区别在于,当达到“automerge”限制时,FTS5 仅开始将 b 树合并在一起。大多数工作是作为后续 INSERT、UPDATE 或 DELETE 操作的一部分执行的。而当达到“危机合并”限制时,违规的 b 树将立即合并。这意味着触发危机合并的 INSERT、UPDATE 或 DELETE 可能需要很长时间才能完成。
默认的“危机合并”值为 16。没有最大限制。尝试将“crisismerge”参数设置为 0 或 1 的值等同于将其设置为默认值 (16)。试图将 'crisismerge' 选项设置为负值是错误的。
INSERT INTO ft(ft, rank) VALUES('crisismerge', 16);
6.3. “删除”命令
此命令仅适用于外部内容和无内容表。它用于从全文索引中删除与单行关联的索引条目。此命令和delete-all 命令是从无内容表的全文索引中删除条目的唯一方法。
为了使用此命令删除一行,必须将文本值“delete”插入到与表同名的特殊列中。要删除的行的rowid 被插入到rowid 列中。插入到其他列中的值必须与当前存储在表中的值相匹配。例如:
-- Insert a row with rowid=14 into the fts5 table.
INSERT INTO ft(rowid, a, b, c) VALUES(14, $a, $b, $c);
-- Remove the same row from the fts5 table.
INSERT INTO ft(ft, rowid, a, b, c) VALUES('delete', 14, $a, $b, $c);
如果作为“删除”命令的一部分“插入”到文本列中的值与当前存储在表中的值不同,则结果可能无法预测。
原因很容易理解:当一个文档被插入到FTS5表中时,全文索引中会增加一个条目来记录每个token在新文档中的位置。删除文档时,需要原始数据以确定需要从全文索引中删除的条目集。因此,如果使用此命令删除行时提供给 FTS5 的数据与插入时用于确定令牌实例集的数据不同,则可能无法正确删除某些全文索引条目,或者 FTS5 可能会尝试删除不存在的索引条目。这会使全文索引处于不可预测的状态,使未来的查询结果不可靠。
6.4. “全部删除”命令
此命令仅适用于外部内容和无内容表。它从全文索引中删除所有条目。
INSERT INTO ft(ft) VALUES('delete-all');
6.5. “完整性检查”命令
此命令用于验证全文索引在内部是否一致,以及是否与任何 外部内容表一致(可选)。
通过将文本值“完整性检查”插入与 FTS5 表同名的特殊列来调用完整性检查命令。如果为“rank”列提供了一个值,则它必须是 0 或 1。例如:
INSERT INTO ft(ft) VALUES('integrity-check');
INSERT INTO ft(ft, rank) VALUES('integrity-check', 0);
INSERT INTO ft(ft, rank) VALUES('integrity-check', 1);
以上三种形式对于所有不是外部内容表的 FTS 表都是等价的。他们检查索引数据结构是否损坏,如果 FTS 表不是无内容的,索引的内容是否与表本身的内容相匹配。
对于外部内容表,如果为排名列指定的值为 1,则仅将索引的内容与外部内容表的内容进行比较。
在所有情况下,如果发现任何差异,命令将失败并出现SQLITE_CORRUPT_VTAB错误。
6.6. “合并”命令
INSERT INTO ft(ft, rank) VALUES('merge', 500);
此命令将 b 树结构合并在一起,直到大约 N 页的合并数据已写入数据库,其中 N 是指定为“合并”命令一部分的参数的绝对值。每个页面的大小由FTS5 pgsz 选项配置。
如果参数为正值,则 B 树结构只有在满足以下任一条件时才有资格合并:
- 在单个级别上有 U 个或更多这样的 b 树(有关 b 树级别的解释,请参阅FTS5 automerge 选项的文档 ),其中 U 是分配给FTS5 usermerge option选项的值。
- 合并已经开始(可能通过指定负参数的“合并”命令)。
通过检查 命令执行前后sqlite3_total_changes() API 返回的值,可以判断“merge”命令是否找到任何要合并在一起的 b 树。如果两个值之间的差异为 2 或更大,则执行工作。如果差异小于 2,则“合并”命令是空操作。在这种情况下,没有理由再次执行相同的“合并”命令,至少在下一次更新 FTS 表之前。
如果该参数为负,并且在 FTS 索引中有不止一层的 B 树结构,则在开始合并操作之前,所有 B 树结构都被分配到同一层。此外,如果参数为负,则不考虑 usermerge 配置选项的值 - 可能只有来自同一级别的两个 b 树可以合并在一起。
上面的意思是执行带有负参数的'merge'命令,直到sqlite3_total_changes()返回值的前后差值 小于2,优化FTS索引的方式与FTS5优化命令相同。但是,如果在此过程进行时将新的 b 树添加到 FTS 索引,FTS5 会将新的 b 树移动到与现有 b 树相同的级别并重新开始合并。为避免这种情况,只有第一次调用“合并”时才应指定一个负参数。对“merge”的每个后续调用都应指定一个正值,以便即使将新的 b 树添加到 FTS 索引,第一次调用启动的合并也会运行完成。
6.7. “优化”命令
此命令将当前构成全文索引的所有单个 b 树合并为一个大型 b 树结构。这确保了全文索引在数据库中占用最少的空间并且以最快的形式进行查询。
有关全文索引及其组件 b 树之间关系的更多详细信息, 请参阅FTS5 automerge 选项的文档。
INSERT INTO ft(ft) VALUES('optimize');
因为它重组了整个 FTS 索引,所以优化命令可能需要很长时间才能运行。FTS5合并命令可用于将优化FTS索引的工作分成多个步骤。去做这个:
- 调用“合并”命令一次,参数设置为 -N,然后
- 将参数设置为 N 调用“合并”命令零次或多次。
其中 N 是每次调用合并命令时要合并的数据页数。当 merge 命令前后 sqlite3_total_changes() 函数返回值的差异降到 2 以下时,应用程序应停止调用 merge。合并命令可以作为相同或单独事务的一部分,由相同或不同的数据库客户端发出。有关详细信息,请参阅 合并命令的文档。
6.8. 'pgsz' 配置选项
此命令用于设置持久性“pgsz”选项。
FTS5 维护的全文索引在数据库表中存储为一系列固定大小的 blob。组成全文索引的所有 blob 不一定都具有相同的大小。pgsz 选项确定由后续索引编写器创建的所有 blob 的大小。默认值为 1000。
INSERT INTO ft(ft, rank) VALUES('pgsz', 4072);
6.9. “等级”配置选项
此命令用于设置持久性“等级”选项。
rank 选项用于更改 rank 列的默认辅助函数映射。该选项应设置为文本值,其格式与“rank MATCH ?”中所述的格式相同。以上条款。例如:
INSERT INTO ft(ft, rank) VALUES('rank', 'bm25(10.0, 5.0)');
6.10. “重建”命令
该命令首先删除整个全文索引,然后根据表或内容表的内容重建它。它不适用于无内容表。
INSERT INTO ft(ft) VALUES('rebuild');
6.11. 'usermerge' 配置选项
此命令用于设置持久的“usermerge”选项。
usermerge 选项类似于 automerge 和 crisismerge 选项。它是将由带有正参数的“合并”命令合并在一起的 B 树段的最小数量。例如:
INSERT INTO ft(ft, rank) VALUES('usermerge', 4);
usermerge 选项的默认值为 4。允许的最小值为 2,最大值为 16。
7.扩展 FTS5
FTS5 具有 API,允许通过以下方式对其进行扩展:
- 添加用 C 实现的新辅助函数,以及
- 添加新的分词器,也是用 C 语言实现的。
本文档中描述的内置分词器和辅助功能都是使用下面描述的公开可用的 API 实现的。
在 FTS5 注册新的辅助功能或分词器实现之前,应用程序必须获得指向“fts5_api”结构的指针。FTS5 扩展注册到的每个数据库连接都有一个 fts5_api 结构。为获取指针,应用程序调用带有单个参数的 SQL 用户定义函数 fts5()。该参数必须设置为指向使用sqlite3_bind_pointer()接口的 fts5_api 对象的指针。以下示例代码演示了该技术:
/*
** Return a pointer to the fts5_api pointer for database connection db.
** If an error occurs, return NULL and leave an error in the database
** handle (accessible using sqlite3_errcode()/errmsg()).
*/
fts5_api *fts5_api_from_db(sqlite3 *db){
fts5_api *pRet = 0;
sqlite3_stmt *pStmt = 0;
if( SQLITE_OK==sqlite3_prepare(db, "SELECT fts5(?1)", -1, &pStmt, 0) ){
sqlite3_bin_pointer(pStmt, (void*)&pRet, "fts5_api_ptr", NULL);
sqlite3_step(pStmt);
}
sqlite3_finalize(pStmt);
return pRet;
}
向后兼容性警告: 在 SQLite 版本 3.20.0 (2017-08-01) 之前,fts5() 的工作方式略有不同。必须修改扩展 FTS5 的旧应用程序才能使用上面显示的新技术。
fts5_api 结构定义如下。它公开了三种方法,一种用于注册新的辅助函数和分词器,另一种用于检索现有的分词器。后者旨在促进类似于内置 porter 分词器的“分词器包装器”的实现。
typedef struct fts5_api fts5_api;
struct fts5_api {
int iVersion; /* Currently always set to 2 */
/* Create a new tokenizer */
int (*xCreateTokenizer)(
fts5_api *pApi,
const char *zName,
void *pContext,
fts5_tokenizer *pTokenizer,
void (*xDestroy)(void*)
);
/* Find an existing tokenizer */
int (*xFindTokenizer)(
fts5_api *pApi,
const char *zName,
void **ppContext,
fts5_tokenizer *pTokenizer
);
/* Create a new auxiliary function */
int (*xCreateFunction)(
fts5_api *pApi,
const char *zName,
void *pContext,
fts5_extension_function xFunction,
void (*xDestroy)(void*)
);
};
要调用 fts5_api 对象的方法,fts5_api 指针本身应作为方法的第一个参数传递,然后是其他方法特定的参数。例如:
rc = pFts5Api->xCreateTokenizer(pFts5Api, ... other args ...);
fts5_api 结构方法在以下部分中单独描述。
7.1. 自定义分词器
要创建自定义分词器,应用程序必须实现三个函数:分词器构造函数 (xCreate)、析构函数 (xDelete) 和执行实际分词的函数 (xTokenize)。每个函数的类型与 fts5_tokenizer 结构的成员变量相同:
typedef struct Fts5Tokenizer Fts5Tokenizer;
typedef struct fts5_tokenizer fts5_tokenizer;
struct fts5_tokenizer {
int (*xCreate)(void*, const char **azArg, int nArg, Fts5Tokenizer **ppOut);
void (*xDelete)(Fts5Tokenizer*);
int (*xTokenize)(Fts5Tokenizer*,
void *pCtx,
int flags, /* Mask of FTS5_TOKENIZE_* flags */
const char *pText, int nText,
int (*xToken)(
void *pCtx, /* Copy of 2nd argument to xTokenize() */
int tflags, /* Mask of FTS5_TOKEN_* flags */
const char *pToken, /* Pointer to buffer containing token */
int nToken, /* Size of token in bytes */
int iStart, /* Byte offset of token within input text */
int iEnd /* Byte offset of end of token within input text */
)
);
};
/* Flags that may be passed as the third argument to xTokenize() */
#define FTS5_TOKENIZE_QUERY 0x0001
#define FTS5_TOKENIZE_PREFIX 0x0002
#define FTS5_TOKENIZE_DOCUMENT 0x0004
#define FTS5_TOKENIZE_AUX 0x0008
/* Flags that may be passed by the tokenizer implementation back to FTS5
** as the third argument to the supplied xToken callback. */
#define FTS5_TOKEN_COLOCATED 0x0001 /* Same position as prev. token */
该实现通过调用 fts5_api 对象的 xCreateTokenizer() 方法注册到 FTS5 模块。如果已经有同名的分词器,则将其替换。如果将非 NULL xDestroy 参数传递给 xCreateTokenizer(),则在关闭数据库句柄或替换分词器时,将使用作为唯一参数传递的 pContext 指针的副本调用它。
如果成功,xCreateTokenizer() 返回 SQLITE_OK。否则,它返回 SQLite 错误代码。在这种情况下,不会调用xDestroy 函数 。
当 FTS5 表使用自定义分词器时,FTS5 核心调用 xCreate() 一次来创建分词器,然后调用 xTokenize() 零次或多次来分词字符串,然后调用 xDelete() 以释放 xCreate() 分配的任何资源。进一步来说:
- x创建:
此函数用于分配和初始化分词器实例。需要一个分词器实例来实际分词文本。
传递给此函数的第一个参数是应用程序在向 FTS5 注册 fts5_tokenizer 对象时提供的 (void*) 指针的副本(xCreateTokenizer() 的第三个参数)。第二个和第三个参数是以 nul 结尾的字符串数组,其中包含标记器参数(如果有),这些参数在标记器名称之后指定为用于创建 FTS5 表的 CREATE VIRTUAL TABLE 语句的一部分。
最后一个参数是一个输出变量。如果成功,应将 (*ppOut) 设置为指向新的分词器句柄并返回 SQLITE_OK。如果发生错误,应返回 SQLITE_OK 以外的某个值。在这种情况下,fts5 假定 *ppOut 的最终值未定义。
- x删除:
调用此函数以删除先前使用 xCreate() 分配的分词器句柄。Fts5 保证每次成功调用 xCreate() 时,该函数将被恰好调用一次。
- xTokenize:
此函数应标记化参数 pText 指示的 nText 字节字符串。pText 可能以也可能不以 nul 终止。传递给此函数的第一个参数是指向 Fts5Tokenizer 对象的指针,该对象由先前调用 xCreate() 返回。
第二个参数表示 FTS5 请求对提供的文本进行标记化的原因。这始终是以下四个值之一:
- FTS5_TOKENIZE_DOCUMENT - 正在将文档插入或从 FTS 表中删除。调用分词器来确定要添加到(或从中删除)FTS 索引的令牌集。
- FTS5_TOKENIZE_QUERY - 正在针对 FTS 索引执行 MATCH 查询。正在调用分词器以分词化指定为查询一部分的裸词或带引号的字符串。
- (FTS5_TOKENIZE_QUERY | FTS5_TOKENIZE_PREFIX) - 与 FTS5_TOKENIZE_QUERY 相同,不同之处在于裸词或引号字符串后跟“*”字符,表示标记器返回的最后一个标记将被视为标记前缀。
- FTS5_TOKENIZE_AUX - 正在调用分词器以满足辅助函数发出的 fts5_api.xTokenize() 请求。或者 fts5_api.xColumnSize() 在 columnsize=0 数据库上发出的请求。
对于输入字符串中的每个标记,必须调用提供的回调 xToken()。它的第一个参数应该是作为第二个参数传递给 xTokenize() 的指针的副本。第三个和第四个参数是指向包含标记文本的缓冲区的指针,以及标记的大小(以字节为单位)。第 4 个和第 5 个参数是输入中从中派生令牌的文本的第一个字节和紧跟其后的第一个字节的字节偏移量。
传递给 xToken() 回调的第二个参数(“tflags”)通常应设置为 0。例外情况是分词器支持同义词。在这种情况下,请参阅下面的讨论以获取详细信息。
FTS5 假设 xToken() 回调是按照每个标记在输入文本中出现的顺序调用的。
如果 xToken() 回调返回 SQLITE_OK 以外的任何值,则应放弃标记化并且 xTokenize() 方法应立即返回 xToken() 返回值的副本。或者,如果输入缓冲区已用完,xTokenize() 应该返回 SQLITE_OK。最后,如果 xTokenize() 实现本身发生错误,它可能会放弃标记化并返回 SQLITE_OK 或 SQLITE_DONE 以外的任何错误代码。
- FTS5_TOKENIZE_DOCUMENT - 正在将文档插入或从 FTS 表中删除。调用分词器来确定要添加到(或从中删除)FTS 索引的令牌集。
7.1.1. 同义词支持
自定义分词器也可能支持同义词。考虑用户希望查询诸如“first place”之类的短语的情况。使用内置分词器,FTS5 查询“first + place”将匹配文档集中“first place”的实例,但不会匹配“第一名”等替代形式。在某些应用程序中,最好匹配“第一名”或“第一名”的所有实例,而不管用户在 MATCH 查询文本中指定的是哪种形式。
在 FTS5 中有几种方法可以解决这个问题:
- 通过将所有同义词映射到单个标记。在这种情况下,使用上面的示例,这意味着分词器为输入“first”和“1st”返回相同的分词。假设令牌实际上是“first”,因此当用户插入文档“I won 1st place”时,条目将添加到令牌“i”、“won”、“first”和“place”的索引中。如果用户随后查询“1st + place”,则分词器将“first”替换为“1st”,查询将按预期进行。
- 通过分别查询每个查询词的所有同义词的索引。在这种情况下,当标记查询文本时,标记器可能会为文档中的单个术语提供多个同义词。FTS5 然后分别查询每个同义词的索引。例如,面对查询:
... MATCH 'first place'
tokenizer 提供“1st”和“first”作为 MATCH 查询中第一个标记的同义词,FTS5 有效地运行类似于以下的查询:
... MATCH '(first OR 1st) place'
除了为了辅助功能的目的,查询似乎仍然只包含两个短语——“(first OR 1st)”被视为一个短语。
- 通过将单个术语的多个同义词添加到 FTS 索引中。使用此方法,在对文档文本进行分词时,分词器会为每个分词提供多个同义词。因此,当诸如“I won first place”之类的文档被标记化时,条目将添加到“i”、“won”、“first”、“1st”和“place”的 FTS 索引中。
这样,即使分词器在分词查询文本时不提供同义词(它不应该 - 这样做效率低下),用户查询“first + place”或“1st + place”也没关系,因为 FTS 索引中有对应于第一个标记的两种形式的条目。
无论是解析文档还是查询文本,对指定带有 FTS5_TOKEN_COLOCATED 位的tflags参数的 xToken 的任何调用都被视为为前一个标记提供同义词。例如,在解析文档“I won first place”时,支持同义词的分词器会调用 xToken() 5 次,如下所示:
xToken(pCtx, 0, "i", 1, 0, 1); xToken(pCtx, 0, "won", 3, 2, 5); xToken(pCtx, 0, "first", 5, 6, 11); xToken(pCtx, FTS5_TOKEN_COLOCATED, "1st", 3, 6, 11); xToken(pCtx, 0, "place", 5, 12, 17);
第一次调用 xToken() 时指定 FTS5_TOKEN_COLOCATED 标志是错误的。通过按顺序多次调用 xToken(FTS5_TOKEN_COLOCATED),可以为单个令牌指定多个同义词。可以为单个令牌提供的同义词的数量没有限制。
在许多情况下,上面的方法 (1) 是最好的方法。它不向 FTS 索引添加额外的数据或要求 FTS5 查询多个术语,因此在磁盘空间和查询速度方面是高效的。但是,它不能很好地支持前缀查询。如果如上所述,标记器将标记“first”替换为“1st”,则查询:
... MATCH '1s*'
不会匹配包含标记“1st”的文档(因为标记器可能不会将“1s”映射到“first”的任何前缀)。
对于完整的前缀支持,方法 (3) 可能是首选。在这种情况下,因为索引包含“first”和“1st”的条目,所以“fi*”或“1s*”等前缀查询将正确匹配。但是,因为额外的条目被添加到 FTS 索引中,所以此方法使用数据库中的更多空间。
方法 (2) 提供了 (1) 和 (3) 之间的中点。使用此方法,诸如“1s*”之类的查询将匹配包含文字标记“1st”但不包含“first”的文档(假设标记器无法提供前缀的同义词)。但是,像“1st”这样的非前缀查询将匹配“1st”和“first”。此方法不需要额外的磁盘空间,因为没有额外的条目添加到 FTS 索引中。另一方面,它可能需要更多的 CPU 周期来运行 MATCH 查询,因为每个同义词都需要单独查询 FTS 索引。
使用方法 (2) 或 (3) 时,重要的是分词器在分词文档文本(方法 (2))或查询文本(方法 (3))时仅提供同义词,而不是同时提供两者。这样做不会导致任何错误,但效率低下。
7.2. 自定义辅助功能
实现自定义辅助函数类似于实现 标量 SQL 函数。实现应该是fts5_extension_function类型的C函数,定义如下:
typedef struct Fts5ExtensionApi Fts5ExtensionApi; typedef struct Fts5Context Fts5Context; typedef struct Fts5PhraseIter Fts5PhraseIter; typedef void (*fts5_extension_function)( const Fts5ExtensionApi *pApi, /* API offered by current FTS version */ Fts5Context *pFts, /* First arg to pass to pApi functions */ sqlite3_context *pCtx, /* Context for returning result/error */ int nVal, /* Number of values in apVal[] array */ sqlite3_value **apVal /* Array of trailing arguments */ );
该实现通过调用 fts5_api 对象的 xCreateFunction() 方法注册到 FTS5 模块。如果已经存在同名的辅助函数,则将其替换为新函数。如果将非 NULL xDestroy 参数传递给 xCreateFunction(),则在关闭数据库句柄或替换已注册的辅助函数时,将使用 pContext 指针的副本作为唯一参数调用它。
如果成功,xCreateFunction() 返回 SQLITE_OK。否则,它返回 SQLite 错误代码。在这种情况下,不会调用xDestroy 函数 。
传递给辅助函数回调的最后三个参数类似于传递给标量 SQL 函数实现的三个参数。除了第一个传递给辅助函数的参数外,所有参数都可用于 apVal[] 数组中的实现。实现应通过内容句柄 pCtx 返回结果或错误。
传递给辅助函数回调的第一个参数是指向包含方法的结构的指针,可以调用这些方法来获取有关当前查询或行的信息。第二个参数是一个不透明的句柄,应该作为第一个参数传递给任何此类方法调用。例如,以下辅助函数定义返回当前行所有列中的标记总数:
/*
** Implementation of an auxiliary function that returns the number
** of tokens in the current row (including all columns).
*/
static void column_size_imp(
const Fts5ExtensionApi *pApi,
Fts5Context *pFts,
sqlite3_context *pCtx,
int nVal,
sqlite3_value **apVal
){
int rc;
int nToken;
rc = pApi->xColumnSize(pFts, -1, &nToken);
if( rc==SQLITE_OK ){
sqlite3_result_int(pCtx, nToken);
}else{
sqlite3_result_error_code(pCtx, rc);
}
}
以下部分详细描述了提供给辅助功能实现的 API。更多示例可以在源代码的“fts5_aux.c”文件中找到。
7.2.1. 自定义辅助函数 API 参考
struct Fts5ExtensionApi {
int iVersion; /* Currently always set to 3 */
void *(*xUserData)(Fts5Context*);
int (*xColumnCount)(Fts5Context*);
int (*xRowCount)(Fts5Context*, sqlite3_int64 *pnRow);
int (*xColumnTotalSize)(Fts5Context*, int iCol, sqlite3_int64 *pnToken);
int (*xTokenize)(Fts5Context*,
const char *pText, int nText, /* Text to tokenize */
void *pCtx, /* Context passed to xToken() */
int (*xToken)(void*, int, const char*, int, int, int) /* Callback */
);
int (*xPhraseCount)(Fts5Context*);
int (*xPhraseSize)(Fts5Context*, int iPhrase);
int (*xInstCount)(Fts5Context*, int *pnInst);
int (*xInst)(Fts5Context*, int iIdx, int *piPhrase, int *piCol, int *piOff);
sqlite3_int64 (*xRowid)(Fts5Context*);
int (*xColumnText)(Fts5Context*, int iCol, const char **pz, int *pn);
int (*xColumnSize)(Fts5Context*, int iCol, int *pnToken);
int (*xQueryPhrase)(Fts5Context*, int iPhrase, void *pUserData,
int(*)(const Fts5ExtensionApi*,Fts5Context*,void*)
);
int (*xSetAuxdata)(Fts5Context*, void *pAux, void(*xDelete)(void*));
void *(*xGetAuxdata)(Fts5Context*, int bClear);
int (*xPhraseFirst)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*, int*);
void (*xPhraseNext)(Fts5Context*, Fts5PhraseIter*, int *piCol, int *piOff);
int (*xPhraseFirstColumn)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*);
void (*xPhraseNextColumn)(Fts5Context*, Fts5PhraseIter*, int *piCol);
};
- void *(*xUserData)(Fts5Context*)
-
返回注册扩展函数的上下文指针的副本。
- int (*xColumnTotalSize)(Fts5Context*, int iCol, sqlite3_int64 *pnToken)
-
如果参数 iCol 小于零,则将输出变量 *pnToken 设置为 FTS5 表中的令牌总数。或者,如果 iCol 为非负数但小于表中的列数,则考虑 FTS5 表中的所有行,返回 iCol 列中的标记总数。
如果参数 iCol 大于或等于表中的列数,则返回 SQLITE_RANGE。或者,如果发生错误(例如 OOM 条件或 IO 错误),则返回适当的 SQLite 错误代码。
- int (*xColumnCount)(Fts5Context*)
-
返回表中的列数。
- int (*xColumnSize)(Fts5Context*, int iCol, int *pnToken)
-
如果参数 iCol 小于零,则将输出变量 *pnToken 设置为当前行中的标记总数。或者,如果 iCol 为非负数但小于表中的列数,则将 *pnToken 设置为当前行的 iCol 列中的标记数。
如果参数 iCol 大于或等于表中的列数,则返回 SQLITE_RANGE。或者,如果发生错误(例如 OOM 条件或 IO 错误),则返回适当的 SQLite 错误代码。
如果与使用“columnsize=0”选项创建的 FTS5 表一起使用,此函数可能效率很低。
- int (*xColumnText)(Fts5Context*, int iCol, const char **pz, int *pn)
-
此函数尝试检索当前文档的 iCol 列的文本。如果成功,(*pz) 被设置为指向包含 utf-8 编码文本的缓冲区,(*pn) 被设置为缓冲区的字节大小(不是字符),并返回 SQLITE_OK。否则,如果发生错误,则返回 SQLite 错误代码,并且 (*pz) 和 (*pn) 的最终值未定义。
- int (*xPhraseCount)(Fts5Context*)
-
返回当前查询表达式中的短语数。
- int (*xPhraseSize)(Fts5Context*, int iPhrase)
-
返回查询的短语 iPhrase 中的标记数。短语从零开始编号。
- int (*xInstCount)(Fts5Context*, int *pnInst)
-
将 *pnInst 设置为当前行中查询中所有短语的总出现次数。如果成功则返回 SQLITE_OK,如果发生错误则返回错误代码(即 SQLITE_NOMEM)。
如果与使用“detail=none”或“detail=column”选项创建的 FTS5 表一起使用,此 API 可能会非常慢。如果 FTS5 表是使用“detail=none”或“detail=column”和“content=”选项创建的(即,如果它是无内容表),则此 API 始终返回 0。
- int (*xInst)(Fts5Context*, int iIdx, int *piPhrase, int *piCol, int *piOff)
-
查询当前行内词组匹配iIdx的详细信息。短语匹配从零开始编号,因此 iIdx 参数应大于或等于零且小于 xInstCount() 输出的值。
通常,输出参数 *piPhrase 设置为短语编号,*piCol 设置为它出现的列,*piOff 设置为短语第一个标记的标记偏移量。如果成功则返回 SQLITE_OK,如果发生错误则返回错误代码(即 SQLITE_NOMEM)。
如果与使用“detail=none”或“detail=column”选项创建的 FTS5 表一起使用,此 API 可能会非常慢。
- sqlite3_int64 (*xRowid)(Fts5Context*)
-
返回当前行的 rowid。
- int (*xTokenize)(Fts5Context*, const char *pText, int nText, 无效* pCtx, int (*xToken)(void*, int, const char*, int, int, int) )
-
使用属于 FTS5 表的分词器对文本进行分词。
- int (*xQueryPhrase)(Fts5Context*, int iPhrase, void *pUserData, int(*)(const Fts5ExtensionApi*,Fts5Context*,void*) )
-
该API函数用于查询FTS表中当前查询的短语iPhrase。具体来说,查询等效于:
... FROM ftstable WHERE ftstable MATCH $p ORDER BY rowid
$p 设置为与当前查询的短语 iPhrase 等价的短语。适用于当前查询的短语 iPhrase 的任何列过滤器都包含在 $p 中。对于访问的每一行,调用作为第四个参数传递的回调函数。传递给回调函数的上下文和 API 对象可用于访问每个匹配行的属性。调用 Api.xUserData() 返回作为第三个参数传递给 pUserData 的指针的副本。
如果回调函数返回 SQLITE_OK 以外的任何值,则放弃查询并且 xQueryPhrase 函数立即返回。如果返回值为 SQLITE_DONE,则 xQueryPhrase 返回 SQLITE_OK。否则,错误代码向上传播。
如果查询顺利完成,则返回 SQLITE_OK。或者,如果在查询完成之前发生错误或被回调中止,则返回 SQLite 错误代码。
- int (*xSetAuxdata)(Fts5Context*, void *pAux, void(*xDelete)(void*))
-
将作为第二个参数传递的指针保存为扩展函数的“辅助数据”。然后可以通过使用 xGetAuxdata() API 作为同一 MATCH 查询的一部分对同一 fts5 扩展函数的当前或任何未来调用来检索该指针。
每个扩展函数为每个 FTS 查询(MATCH 表达式)分配一个单独的辅助数据槽。如果为单个 FTS 查询多次调用扩展函数,则所有调用共享一个辅助数据上下文。
如果调用此函数时已经存在辅助数据指针,则将其替换为新指针。如果 xDelete 回调与原始指针一起指定,则此时调用它。
如果指定了 xDelete 回调,也会在 FTS5 查询完成后对辅助数据指针调用。
如果此函数中发生错误(例如 OOM 条件),则辅助数据将设置为 NULL 并返回错误代码。如果 xDelete 参数不为 NULL,则在返回之前在辅助数据指针上调用它。
- void *(*xGetAuxdata)(Fts5Context*, int bClear)
-
返回 fts5 扩展函数的当前辅助数据指针。有关详细信息,请参阅 xSetAuxdata() 方法。
如果 bClear 参数不为零,则在此函数返回之前清除辅助数据(设置为 NULL)。在这种情况下,不会调用 xDelete(如果有)。
- int (*xRowCount)(Fts5Context*, sqlite3_int64 *pnRow)
-
此函数用于检索表中的总行数。换句话说,将返回相同的值:
SELECT count(*) FROM ftstable;
- int (*xPhraseFirst)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*, int*)
-
此函数与类型 Fts5PhraseIter 和 xPhraseNext 方法一起用于循环访问当前行中单个查询短语的所有实例。这与可通过 xInstCount/xInst API 访问的信息相同。虽然 xInstCount/xInst API 使用起来更方便,但在某些情况下此 API 可能更快。要遍历短语 iPhrase 的实例,请使用以下代码:
Fts5PhraseIter iter; int iCol, iOff; for(pApi->xPhraseFirst(pFts, iPhrase, &iter, &iCol, &iOff); iCol>=0; pApi->xPhraseNext(pFts, &iter, &iCol, &iOff) ){ // An instance of phrase iPhrase at offset iOff of column iCol }Fts5PhraseIter 结构在上面定义。应用程序不应直接修改此结构 - 它只能如上所示与 xPhraseFirst() 和 xPhraseNext() API 方法(以及 xPhraseFirseFirstColumn() 和 xPhraseNextColumn() 一起使用,如下图所示)。
如果与使用“detail=none”或“detail=column”选项创建的 FTS5 表一起使用,此 API 可能会非常慢。如果 FTS5 表是使用“detail=none”或“detail=column”和“content=”选项创建的(即,如果它是无内容表),则此 API 始终遍历空集(所有调用 xPhraseFirst( ) 将 iCol 设置为 -1)。
- void (*xPhraseNext)(Fts5Context*, Fts5PhraseIter*, int *piCol, int *piOff)
-
请参见上面的 xPhraseFirst。
- int (*xPhraseFirstColumn)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*)
-
此函数和 xPhraseNextColumn() 类似于上述的 xPhraseFirst() 和 xPhraseNext() API。不同之处在于,这些 API 不是循环访问当前行中短语的所有实例,而是用于循环访问当前行中包含一个或多个指定短语实例的列集。例如:
Fts5PhraseIter iter; int iCol; for(pApi->xPhraseFirstColumn(pFts, iPhrase, &iter, &iCol); iCol>=0; pApi->xPhraseNextColumn(pFts, &iter, &iCol) ){ // Column iCol contains at least one instance of phrase iPhrase }如果与使用“detail=none”选项创建的 FTS5 表一起使用,此 API 可能会非常慢。如果 FTS5 表是使用“detail=none”“content=”选项创建的(即,如果它是无内容表),则此 API 始终遍历空集(对 xPhraseFirstColumn() 的所有调用都将 iCol 设置为 -1) .
使用此 API 及其配套的 xPhraseFirstColumn() 访问的信息也可以使用 xPhraseFirst/xPhraseNext(或 xInst/xInstCount)获得。这个 API 的主要优点是,当与“detail=column”表一起使用时,它比那些替代方法更有效。
- void (*xPhraseNextColumn)(Fts5Context*, Fts5PhraseIter*, int *piCol)
-
请参阅上面的 xPhraseFirstColumn。
8. fts5vocab 虚拟表模块
fts5vocab 虚拟表模块允许用户直接从 FTS5 全文索引中提取信息。fts5vocab 模块是 FTS5 的一部分——只要有 FTS5,它就可用。
每个 fts5vocab 表都与一个 FTS5 表相关联。通常通过在 CREATE VIRTUAL TABLE 语句中指定两个参数代替列名来创建 fts5vocab 表 - 关联的 FTS5 表的名称和 fts5vocab 表的类型。目前有三种类型的fts5vocab表;“行”、“列”和“实例”。除非 fts5vocab 表是在“临时”数据库中创建的,否则它必须是与关联的 FTS5 表相同的数据库的一部分。
-- Create an fts5vocab "row" table to query the full-text index belonging
-- to FTS5 table "ft1".
CREATE VIRTUAL TABLE ft1_v USING fts5vocab('ft1', 'row');
-- Create an fts5vocab "col" table to query the full-text index belonging
-- to FTS5 table "ft2".
CREATE VIRTUAL TABLE ft2_v USING fts5vocab(ft2, col);
-- Create an fts5vocab "instance" table to query the full-text index
-- belonging to FTS5 table "ft3".
CREATE VIRTUAL TABLE ft3_v USING fts5vocab(ft3, instance);
如果在临时数据库中创建了一个 fts5vocab 表,它可能与任何附加数据库中的 FTS5 表相关联。为了将 fts5vocab 表附加到位于“temp”以外的数据库中的 FTS5 表,数据库的名称被插入到 CREATE VIRTUAL TABLE 参数中的 FTS5 表名之前。例如:
-- Create an fts5vocab "row" table to query the full-text index belonging
-- to FTS5 table "ft1" in database "main".
CREATE VIRTUAL TABLE temp.ft1_v USING fts5vocab(main, 'ft1', 'row');
-- Create an fts5vocab "col" table to query the full-text index belonging
-- to FTS5 table "ft2" in attached database "aux".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft2, col);
-- Create an fts5vocab "instance" table to query the full-text index
-- belonging to FTS5 table "ft3" in attached database "other".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft3, 'instance');
在“temp”以外的任何数据库中创建 fts5vocab 表时指定三个参数会导致错误。
“行”类型的 fts5vocab 表包含关联 FTS5 表中每个不同术语的一行。表格列如下:
| Column | Contents |
|---|---|
| term | The term, as stored in the FTS5 index. |
| doc | The number of rows that contain at least one instance of the term. |
| cnt | The total number of instances of the term in the entire FTS5 table. |
“col”类型的 fts5vocab 表包含关联 FTS5 表中每个不同术语/列组合的一行。表列如下:
| Column | Contents |
|---|---|
| term | The term, as stored in the FTS5 index. |
| col | The name of the FTS5 table column that contains the term. |
| doc | The number of rows in the FTS5 table for which column $col contains at least one instance of the term. |
| cnt | The total number of instances of the term that appear in column $col of the FTS5 table (considering all rows). |
“instance”类型的 fts5vocab 表包含存储在关联 FTS 索引中的每个术语实例的一行。假设创建 FTS5 表时将“详细信息”选项设置为“完整”,表列如下:
| Column | Contents |
|---|---|
| term | The term, as stored in the FTS5 index. |
| doc | The rowid of the document that contains the term instance. |
| col | The name of the column that contains the term instance. |
| offset | The index of the term instance within its column. Terms are numbered in order of occurrence starting from 0. |
如果创建 FTS5 表时将“详细信息”选项设置为“col”,则实例虚拟表的偏移量列始终包含 NULL。在这种情况下,表中每个唯一的术语/文档/列组合都有一行。或者,如果创建 FTS5 表时将“detail”设置为“none”,则offset和col始终包含 NULL 值。对于 detail=none FTS5 表,fts5vocab 表中有一行用于每个唯一的术语/文档组合。
例子:
-- Assuming a database created using:
CREATE VIRTUAL TABLE ft1 USING fts5(c1, c2);
INSERT INTO ft1 VALUES('apple banana cherry', 'banana banana cherry');
INSERT INTO ft1 VALUES('cherry cherry cherry', 'date date date');
-- Then querying the following fts5vocab table (type "col") returns:
--
-- apple | c1 | 1 | 1
-- banana | c1 | 1 | 1
-- banana | c2 | 1 | 2
-- cherry | c1 | 2 | 4
-- cherry | c2 | 1 | 1
-- date | c3 | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_col USING fts5vocab(ft1, col);
-- Querying an fts5vocab table of type "row" returns:
--
-- apple | 1 | 1
-- banana | 1 | 3
-- cherry | 2 | 5
-- date | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_row USING fts5vocab(ft1, row);
-- And, for type "instance"
INSERT INTO ft1 VALUES('apple banana cherry', 'banana banana cherry');
INSERT INTO ft1 VALUES('cherry cherry cherry', 'date date date');
--
-- apple | 1 | c1 | 0
-- banana | 1 | c1 | 1
-- banana | 1 | c2 | 0
-- banana | 1 | c2 | 1
-- cherry | 1 | c1 | 2
-- cherry | 1 | c2 | 2
-- cherry | 2 | c1 | 0
-- cherry | 2 | c1 | 1
-- cherry | 2 | c1 | 2
-- date | 2 | c2 | 0
-- date | 2 | c2 | 1
-- date | 2 | c2 | 2
--
CREATE VIRTUAL TABLE ft1_v_instance USING fts5vocab(ft1, instance);
9. FTS5数据结构
本节简要介绍 FTS 模块在数据库中存储其索引和内容的方式。无需阅读或理解本节中的材料即可在应用程序中使用 FTS。但是,对于尝试分析和理解 FTS 性能特征的应用程序开发人员,或者对于考虑增强现有 FTS 功能集的开发人员来说,它可能很有用。
在数据库中创建 FTS5 虚拟表时,会在数据库中创建 3 到 5 个真实表。这些被称为“影子表”,虚拟表模块使用它们来存储持久数据。用户不应直接访问它们。许多其他虚拟表模块,包括 FTS3和rtree,也创建和使用影子表。
FTS5 创建以下影子表。在每种情况下,实际表名都基于 FTS5 虚拟表的名称(在下文中,将 % 替换为虚拟表的名称以查找实际的影子表名)。
-- This table contains most of the full-text index data. CREATE TABLE %_data(id INTEGER PRIMARY KEY, block BLOB); -- This table contains the remainder of the full-text index data. -- It is almost always much smaller than the %_data table. CREATE TABLE %_idx(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID; -- Contains the values of persistent configuration parameters. CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID; -- Contains the size of each column of each row in the virtual table -- in tokens. This shadow table is not present if the "columnsize" -- option is set to 0. CREATE TABLE %_docsize(id INTEGER PRIMARY KEY, sz BLOB); -- Contains the actual data inserted into the FTS5 table. There -- is one "cN" column for each indexed column in the FTS5 table. -- This shadow table is not present for contentless or external -- content FTS5 tables. CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
以下部分更详细地描述了如何使用这五个表来存储 FTS5 数据。
9.1. 变量格式
以下部分涉及以“varint”形式存储的 64 位有符号整数。FTS5 使用与 SQLite 核心在不同地方使用的相同的 varint 格式。
varint 的长度在 1 到 9 个字节之间。varint 由零个或多个字节组成,其中高位设置后跟一个高位清除的单个字节,或者九个字节,以较短者为准。前八个字节的低七位和第九个字节的所有 8 位用于重建 64 位二进制补码整数。Varint 是大端字节序的:从 varint 的较早字节中提取的位比从后面字节中提取的位更重要。
9.2. FTS 索引(%_idx 和 %_data 表)
FTS 索引是一个有序的键值存储,其中键是文档术语或术语前缀,关联的值是“doclists”。doclist 是一个打包的 varint 数组,它对术语的每个实例在 FTS5 表中的位置进行编码。单个术语实例的位置定义为以下组合:
- 它出现在 FTS5 表行的 rowid,
- 术语实例出现的列的索引(列从零开始从左到右编号),以及
- 术语在列值中的偏移量(即在该列值之前出现在列值中的标记数)。
FTS 索引包含数据集中每个标记的最多 (nPrefix+1) 个条目,其中 nPrefix 是定义的 前缀索引的数量。
与主 FTS 索引(不是前缀索引的索引)关联的键以字符“0”为前缀。第一个前缀索引的键以“1”为前缀。第二个前缀索引的键以“2”为前缀,依此类推。例如,如果将标记“document”插入到具有由 prefix="2 4" 指定的前缀索引的 FTS5 表中 ,则添加到 FTS 索引的键将是 "0document"、"1do" 和 "2docu"。
FTS 索引条目不存储在单个树或哈希表结构中。相反,它们存储在一系列不可变的 b 树类结构中,称为“段 b 树”。每次提交对 FTS5 表的写入时,都会添加一个或多个(但通常只有一个)新段 B 树,其中包含新条目和任何已删除条目的墓碑。查询FTS索引时,reader依次查询每段b-tree,并合并结果,优先选择较新的数据。
每个段 b-tree 都分配了一个数字级别。当一个新的段 b-tree 作为提交事务的一部分写入数据库时,它被分配到级别 0。属于单个级别的段 b-tree 定期合并在一起以创建单个更大的段 b-tree被分配到下一层(即 0 级段 b 树被合并成为单个 1 级段 b 树)。因此,数值较大的级别在(通常)较大的段 b 树中包含较旧的数据。有关如何控制合并的详细信息, 请参阅 'automerge'、 'crisismerge'和 'usermerge'选项,以及 'merge'和 'optimize'命令。
在与术语或术语前缀关联的文档列表非常大的情况下,可能会有关联的文档列表索引。doclist 索引类似于 b 树的一组内部节点。它允许在大型文档列表中有效地查询 rowids 或 rowids 范围。例如,在处理如下查询时:
SELECT ... FROM fts_table('term') WHERE rowid BETWEEN ? AND ?
FTS5 使用段 b 树索引来定位术语“term”的文档列表,然后使用其文档列表索引(假设它存在)有效地识别所需范围内与 rowids 匹配的子集。
9.2.1. %_data 表 Rowid 空间
CREATE TABLE %_data( id INTEGER PRIMARY KEY, block BLOB );
%_data 表用于存储三种类型的记录:
- 特殊结构记录,以id=1存储。
- 特殊平均值记录,以 id=10 存储。
- 一个记录来存储每个段的 b-tree 叶子和doclist 索引叶子和内部节点。请参阅下文了解如何为这些记录计算 id 值。
系统中的每个段 b 树都分配有一个唯一的 16 位段 ID。段 id 只能在原始所有者段 b-tree 完全合并到更高级别的段 b-tree 后才能重用。在段 b-tree 中,每个叶页都分配有一个唯一的页码 - 第一个叶页为 1,第二个叶页为 2,依此类推。
每个 doclist 索引叶页也分配了一个页码。doclist 索引中的第一个(最左边的)叶页被分配了与其术语出现的段 b-tree 叶页相同的页码(因为 doclist 索引仅为具有非常长的 doclists 的术语创建,每个段最多一个术语b-tree 叶子有一个相关的 doclist 索引)。称此页码为 P。如果文档列表太大以至于需要第二个叶子,则第二个叶子的页码为 P+1。第三片叶子P+2。doclist 索引 b 树的每一层(叶子、叶子的父代、祖父母等)都以这种方式分配页码,从页码 P 开始。
%_data 表中用于存储任何给定段 b 树叶或 doclist 索引叶或节点的“id”值组成如下:
| Rowid Bits | Contents |
|---|---|
| 38..43 | (16 bit) Segment b-tree id value. |
| 37 | (1 bit) Doclist index flag. Set for doclist index pages, clear for segment b-tree leaves. |
| 32..36 | (5 bits) Height in tree. This is set to 0 for segment b-tree and doclist index leaves, to 1 for the parents of doclist index leaves, 2 for the grandparents, etc. |
| 0..31 | (32 bits) Page number |
9.2.2. 结构记录格式
结构记录标识构成当前 FTS 索引的段 b 树集,以及任何正在进行的增量合并操作的详细信息。它存储在 id=1 的 %_data 表中。结构记录以单个 32 位无符号值开始 - cookie 值。每次修改结构时,该值都会递增。cookie 值之后是三个 varint 值,如下所示:
- 索引中的级别数(即与任何段 b-tree 相关联的最大级别加一)。
- 索引中段 b 树的总数。
- 自创建 FTS5 表以来写入 0 级树的段 b 树叶总数。
然后,对于从 0 到 nLevel 的每个级别:
- 来自上一级别的输入段的数量被用作当前增量合并的输入,或者如果没有正在进行的增量合并来为该级别创建新的段 b 树,则为零。
- 该级别上的段 b 树总数。
- 然后,对于每个段 b-tree,从最旧到最新:
- 段 ID。
- 第一页的页码(通常为 1,总是 >0)。
- 最后一页的页码(总是 >0)。
9.2.3. 平均记录格式
在 %_data 表中始终以 id=10 存储的平均值记录不存储任何平均值。相反,它包含一个包含 (nCol+1) 个打包 varint 值的向量,其中 nCol 是 FTS5 表中的列数,包括未索引的列。第一个 varint 包含 FTS5 表中的总行数。第二个包含存储在最左侧 FTS5 表列中的所有值中的标记总数。第三个是下一个最左边的所有值中的标记数,依此类推。未索引列的值始终为零。
9.2.4. 段 B 树格式
9.2.4.1. 密钥/文档列表格式
键/文档列表格式是一种用于按排序顺序存储一系列键(以单个字符为前缀的文档术语或术语前缀,以标识它们所属的特定索引)的格式,每个键及其关联的文档列表。该格式由打包在一起的交替键和文档列表组成。
第一个密钥存储为:
- 指示密钥 (N) 中字节数的 varint,后跟
- 密钥数据本身(N 字节)。
每个后续密钥存储为:
- 一个 varint,指示该键与前一个键共有的前缀大小(以字节为单位),
- 一个 varint,指示在公共前缀 (N) 之后的密钥中的字节数,后跟
- 密钥后缀数据本身(N 字节)。
例如,如果 FTS5 密钥/文档列表记录中的前两个密钥是“0challenger”和“0chandelier”,则第一个密钥存储为 varint 11,后跟 11 个字节“0challenger”,第二个密钥存储为 varints 4 和 7,后跟 7 个字节“ndelier”。
图 1 - 术语/文档列表格式
每个 doclist 标识包含至少一个术语或术语前缀实例和关联位置列表的行(通过它们的 rowid 值),或者“poslist”枚举行中每个术语实例的位置。从这个意义上说,“位置”被定义为列号和列值内的术语偏移量。
在 doclist 中,文档总是按 rowid 排序的顺序存储。doclist 中的第一个 rowid 按原样存储为 varint。它后面紧跟其关联的位置列表。在此之后,第一个 rowid 和第二个之间的差异,作为 varint,然后是与文档列表中的第二个 rowid 关联的文档列表。等等。
无法通过解析来确定文档列表的大小。这必须存储在外部。有关如何在 FTS5 中完成此操作的详细信息, 请参阅以下部分。
图 2 - 文档列表格式
位置列表——通常缩写为“poslist”——标识所讨论令牌的每个实例的行内的列和令牌偏移量。一个 poslist 的格式是:
- Varint 设置为 poslist 大小的两倍,不包括此字段,如果在条目上设置了“删除”标志,则加一。
- 行的第 0 列(最左边的列)的偏移量列表(可能为空)。每个偏移量都存储为一个 varint。第一个 varint 包含第一个偏移量的值,加上 2。第二个变量包含第二个和第一个偏移量之间的差值,加上 2。等等。例如,如果偏移量列表包含偏移量 0、10、15 和 16 ,它通过打包以下值进行编码,编码为 varints,端到端:
2, 12, 7, 3
- 对于除第 0 列之外的每一列,它包含一个标记的多个实例:
- 字节值 0x01。
- 列号,作为 varint。
- 一个偏移量列表,其格式与第 0 列的偏移量列表相同。
图 3 - 位置列表 (poslist) 在第 0 和 i 列中有偏移量
9.2.4.2. 分页
如果它足够小(默认情况下这意味着小于 4000 字节),则段 b-tree 的全部内容可以存储在上一节中描述的键/文档列表格式中作为 %_data 表中的单个 blob。否则,键/文档列表被分成几页(默认情况下,每页大约 4000 字节)并存储在 %_data 表中的一组连续条目中(详见上文)。
key/doclist 分页时,对格式做如下修改:
- 单个 varint 或关键数据字段永远不会跨越两页。
- 每个页面上的第一个键没有前缀压缩。它以上述格式存储在文档列表的第一个键中——其大小为 varint,后跟键数据。
- 如果页面上第一个键之前有一个或多个 rowid,则其中第一个不会进行增量压缩。它按原样存储,就好像它是其文档列表的第一个 rowid(它可能是也可能不是)。
每个页面还有固定大小的 4 字节页眉和可变大小的页脚。标头分为 2 个 16 位大端整数字段。他们包含:
- 页面上第一个 rowid 值的字节偏移量,如果它出现在第一个键之前,否则为 0。
- 页脚的字节偏移量。
页脚由一系列 varint 组成,其中包含出现在页面上的每个键的字节偏移量。如果页面上没有键,页脚的大小为零字节。
图 4 - 页面格式
9.2.4.3. 段索引格式
将 segment b-tree 的内容格式化为 key/doclist 格式,然后将其拆分为页面的结果与 b+tree 的叶子非常相似。不是为这个 b+tree 的内部节点创建格式并将它们存储在叶子旁边的 %_data 表中,而是将存储在这些节点上的键添加到 %_idx 表中,定义为:
CREATE TABLE %_idx( segid INTEGER, -- segment id term TEXT, -- prefix of first key on page pgno INTEGER, -- (2*pgno + bDoclistIndex) PRIMARY KEY(segid, term) );
对于包含至少一个键的每个“叶”页,一个条目被添加到 %_idx 表中。字段设置如下:
| Column | Contents |
|---|---|
| segid | The integer segment id. |
| term | The smallest prefix of the first key on the page that is larger than all keys on the previous page. For the first page in a segment, this prefix is zero bytes in size. |
| pgno | This field encodes both the page number (within the
segment - starting from 1) and the doclist index flag.
The doclist index flag is set if the final key on the
page has an associated
doclist index. The value of this field is:
(pgno*2 + bDoclistIndexFlag) |
然后,为了找到可能包含术语 t 的段 i 的叶子,而不是通过内部节点搜索,FTS5 运行查询:
SELECT pgno FROM %_idx WHERE segid=$i AND term>=$t ORDER BY term LIMIT 1
9.2.4.4. 文档列表索引格式
上一节中描述的段索引允许按术语或假设存在所需大小的前缀索引、术语前缀来有效地查询段 b 树。本节中描述的数据结构,doclist 索引,允许 FTS5 在与单个术语或术语前缀关联的 doclist 中有效地搜索 rowid 或范围或 rowids。
并非所有键都有关联的文档列表索引。默认情况下,如果 doclist 跨越超过 4 个段的 b-tree 叶页,则只为键添加 doclist 索引。Doclist 索引本身是 b 树,叶子和内部节点都存储为 %_data 表中的条目,但实际上大多数 doclists 足够小以适合单个叶子。FTS5 对 doclist 索引节点和叶子使用与段 b 树叶子相同的粗略大小(默认为 4000 字节)。
Doclist 索引叶和内部节点使用相同的页面格式。第一个字节是“标志”字节。doclist 索引 b 树的根页面设置为 0x00,所有其他页面设置为 0x01。该页面的其余部分是一系列紧凑的 varint,如下所示:
- 最左边子页的页码,后跟
- 最左侧子页面上的最小 rowid 值,然后是
- 每个后续子页面一个 varint,包含值:
- 0x00 如果子页面上没有 rowid(这只会发生在“子”页面实际上是段 b 树叶子时),或者
- 子页面上最小的 rowid 与存储在 doclist 索引页面上的前一个 rowid 值之间的差异。
对于 doclist 索引中最左边的 doclist 索引叶,最左边的子页是包含键本身的页之后的第一个段 b-tree 叶。
9.3. 文档大小表(%_docsize 表)
CREATE TABLE %_docsize(
id INTEGER PRIMARY KEY, -- id of FTS5 row this record pertains to
sz BLOB -- blob containing nCol packed varints
);
许多常见的搜索结果排名函数需要输入结果文档的标记大小(因为在短文档中命中的搜索词被认为比在长文档中命中的搜索词更重要)。为了提供对此信息的快速访问,对于 FTS5 表中的每一行,在 %_docsize 影子表中存在一个对应的记录(具有相同的 rowid),其中包含行中每个列值的大小,以标记为单位。
列值大小存储在一个 blob 中,该 blob 从左到右包含 FTS5 表的每一列的一个打包 varint。当然,varint 包含相应列值中的标记总数。未索引的列包含在此 varint 向量中;对他们而言,该值始终设置为零。
该表由xColumnSize API 使用。可以通过指定 columnsize=0选项将其完全省略。在这种情况下,xColumnSize API 仍可用于辅助函数,但运行速度要慢得多。
9.4. 表格内容(%_content 表格)
CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
实际的表内容——插入到 FTS5 表中的值,存储在 %_content 表中。创建此表时,FTS5 表的每一列都有一个“c*”列,包括任何未索引的列。最左边的 FTS5 表列的值存储在 %_content 表的“c0”列中,下一个 FTS5 表列中的值存储在“c1”列中,依此类推。
对于外部内容或无内容的FTS5 表,此表完全省略。表。
9.5. 配置选项(%_config 表)
CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID;
该表存储任何持久配置选项的值。“k”列存储选项的名称(文本),“v”列存储值。示例内容:
sqlite> SELECT * FROM fts_tbl_config; ┌─────────────┬──────┐ │ k │ v │ ├─────────────┼──────┤ │ crisismerge │ 8 │ │ pgsz │ 8000 │ │ usermerge │ 4 │ │ version │ 4 │ └─────────────┴──────┘
附录 A:与 FTS3/4 的比较
同样可用的是类似但更成熟的FTS3/4模块。FTS5 是 FTS4 的新版本,其中包括针对 FTS4 中无法在不牺牲向后兼容性的情况下修复的问题的各种修复和解决方案。下面描述了其中一些问题 。
应用程序移植指南
为了使用 FTS5 而不是 FTS3 或 FTS4,应用程序通常需要最少的修改。其中大部分分为三类 - 用于创建 FTS 表的 CREATE VIRTUAL TABLE 语句所需的更改、用于对表执行查询的 SELECT 查询所需的更改以及使用FTS 辅助功能的应用程序所需的更改。
对 CREATE VIRTUAL TABLE 语句的更改
-
模块名称必须从“fts3”或“fts4”更改为“fts5”。
-
必须从列定义中删除所有类型信息或约束规范。FTS3/4 忽略列定义中列名后面的所有内容,FTS5 尝试解析它(如果失败将报告错误)。
-
“matchinfo=fts3”选项不可用。“ columnsize=0”选项是等效的。
-
notindexed= 选项不可用。将UNINDEXED添加 到列定义是等效的。
-
ICU 分词器不可用。
-
compress=、uncompress= 和 languageid= 选项不可用。到目前为止,它们的功能还没有等价物。
-- FTS3/4 statement CREATE VIRTUAL TABLE t1 USING fts4( linkid INTEGER, header CHAR(20), text VARCHAR, notindexed=linkid, matchinfo=fts3, tokenizer=unicode61 ); -- FTS5 equivalent (note - the "tokenizer=unicode61" option is not -- required as this is the default for FTS5 anyway) CREATE VIRTUAL TABLE t1 USING fts5( linkid UNINDEXED, header, text, columnsize=0 );
对 SELECT 语句的更改
-
“docid”别名不存在。应用程序必须改用“rowid”。
-
当列过滤器被指定为 FTS 查询的一部分和使用列作为 MATCH 运算符的 LHS 时,查询的行为略有不同。对于包含“a”和“b”列的表以及类似于以下内容的查询:
... a MATCH 'b: string'
FTS3/4 在“b”列中搜索匹配项。但是,FTS5 总是返回零行,因为结果首先针对“b”列进行过滤,然后针对“a”列进行过滤,没有留下任何结果。换句话说,在 FTS3/4 中,内部过滤器覆盖外部过滤器,在 FTS5 中,两个过滤器都被应用。
-
FTS 查询语法(MATCH 运算符的右侧)在某些方面发生了变化。FTS5 语法非常接近 FTS4“增强语法”。主要区别在于 FTS5 对无法识别的标点符号和查询字符串中的相似字符更加挑剔。大多数适用于 FTS3/4 的查询也应该适用于 FTS5,而那些不适用于 FTS5 的查询应该返回解析错误。
辅助功能变化
FTS5 没有 matchinfo() 或 offsets() 函数,并且 snippet() 函数不像 FTS3/4 中那样功能齐全。但是,由于 FTS5 确实提供了允许应用程序创建自定义辅助功能的 API ,因此可以在应用程序代码中实现任何所需的功能。
FTS5 提供的内置辅助功能集可能会在未来得到改进。
其他问题
fts4aux 模块提供的功能现在由fts5vocab提供。这两个表的架构略有不同。
FTS3/4“merge=X,Y”命令已被 FTS5 合并命令取代。
FTS3/4“automerge=X”命令已被 FTS5 automerge 选项取代。
技术差异总结
FTS5 与 FTS3/4 相似,因为两者的主要任务是维护从每个唯一标记到一组文档中该标记的实例列表的索引映射,其中每个实例由它出现的文档标识及其在该文件中的位置。例如:
-- Given the following SQL: CREATE VIRTUAL TABLE ft USING fts5(a, b); INSERT INTO ft(rowid, a, b) VALUES(1, 'X Y', 'Y Z'); INSERT INTO ft(rowid, a, b) VALUES(2, 'A Z', 'Y Y'); -- The FTS5 module creates the following mapping on disk: A --> (2, 0, 0) X --> (1, 0, 0) Y --> (1, 0, 1) (1, 1, 0) (2, 1, 0) (2, 1, 1) Z --> (1, 1, 1) (2, 0, 1)
在上面的示例中,每个三元组通过 rowid、列号(列从 0 从左到右开始按顺序编号)和列值内的位置(列值中的第一个标记为 0,第二个是 1,依此类推)。使用此索引,FTS5 能够及时回答查询,例如“包含标记 'A' 的所有文档的集合”或“包含序列 'Y Z' 的所有文档的集合”。与单个令牌关联的实例列表称为“实例列表”。
FTS3/4 和 FTS5 之间的主要区别在于,在 FTS3/4 中,每个实例列表存储为单个大型数据库记录,而在 FTS5 中,大型实例列表分为多个数据库记录。这对处理包含大型列表的大型数据库有以下影响:
-
FTS5 能够以增量方式将实例列表加载到内存中,以减少内存使用和峰值分配大小。FTS3/4 经常将整个实例列表加载到内存中。
-
当处理具有多个标记的查询时,FTS5 有时能够通过检查大型实例列表的子集来确定可以回答查询。FTS3/4 几乎总是要遍历整个实例列表。
- 如果实例列表增长到超过SQLITE_MAX_LENGTH限制,FTS3/4 将无法处理它。FTS5 没有这个问题。
由于这些原因,许多复杂的查询可能会使用更少的内存并使用 FTS5 运行得更快。
FTS5 与 FTS3/4 的其他一些不同之处包括:
-
FTS5 支持“ORDER BY rank”以按相关性递减的顺序返回结果。
-
FTS5 具有一个 API,允许用户为高级排名和文本处理应用程序创建自定义辅助功能。特殊的“rank”列可以映射到自定义辅助函数,以便将“ORDER BY rank”添加到查询中可以按预期工作。
-
默认情况下,FTS5 识别 unicode 分隔符和大小写等效。这也可以使用 FTS3/4,但必须明确启用。
-
查询语法已在必要时进行了修订,以消除歧义并使转义查询术语中的特殊字符成为可能。
-
默认情况下,FTS3/4 有时会在用户执行的 INSERT、UPDATE 或 DELETE 语句中合并两个或多个构成其全文索引的 b 树。这意味着对 FTS3/4 表的任何操作都可能出奇地慢,因为 FTS3/4 可能会意外地选择将其中的两个或更多大 b 树合并在一起。FTS5 默认使用增量合并,这限制了在任何给定的 INSERT、UPDATE 或 DELETE 操作中可能发生的处理量。